
使用 DCGAN 生成动漫小姐姐头像

生成对抗网络是 2014 年由伊恩·古德费洛等人提出的一种非监督式学习方法 arXiv:1406.2661v1,该方法的特点是通过让两个神经网络相互博弈的方式进行学习。DCGAN 是 GAN 的一种十分实用的延伸网络,它由 Alec Radford 等人于 2015 年提出 arXiv:1511.06434。
DCGAN 的全称为:Deep Convolutional Generative Adversarial Networks,翻译成中文也就是:深度卷积生成对抗网络。DCGAN 将卷积网络引入到生成式模型当中来做无监督的训练。这种结构很好地利用了卷积网络强大的特征提取能力,从而有效提高了生成网络的学习效果。
数据集
首先,你需要找到一些动漫人物头像数据。不用特别多,几千张就可以了。这里推荐一个网站 Danbooru,可以直接使用爬虫爬取。

网络搭建
我们可以使用 TensorFlow 或者 PyTorch 来构建网络。这里推荐使用 PyTorch,因为其提供的 Dataloader 数据加载器非常适合用来对图像进行预处理和小批量加载。
下面提供一段示例代码,你需要将头像图片放置在 avatar 目录下方。
import torch
from torchvision import datasets, transforms
# 定义图片处理方法
transforms = transforms.Compose([
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = datasets.ImageFolder('avatar/',
transform=transforms)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=16,
shuffle=True,
num_workers=2
)
网络主体需要参考 DCGAN 论文来实现,下面是 DCGAN 网络结构图。
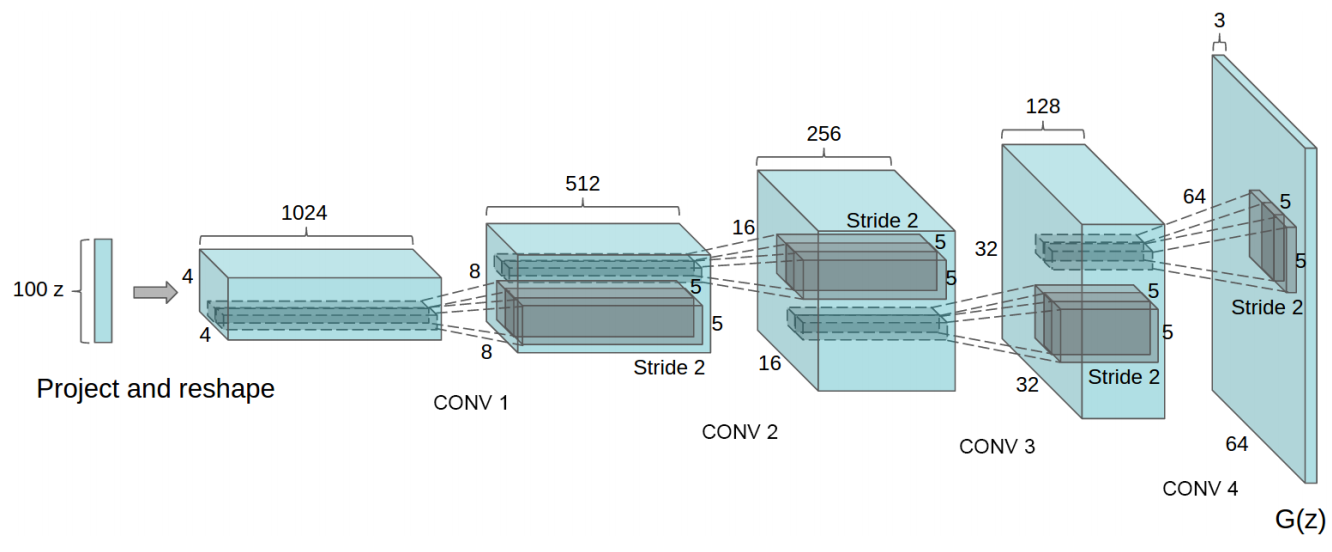
结合网络结构图,就可以实现生成器和判别器网络了。
from torch import nn
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d( 100, 64 * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(64 * 8),
nn.ReLU(True),
nn.ConvTranspose2d(64 * 8, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.ReLU(True),
nn.ConvTranspose2d( 64 * 4, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.ReLU(True),
nn.ConvTranspose2d( 64 * 2, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d( 64, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 2, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 4, 64 * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64 * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
定义损失函数和优化器是必不可少的步骤:
netD = Discriminator()
netG = Generator()
criterion = nn.BCELoss()
lr = 0.0002
optimizerD = torch.optim.Adam(netD.parameters(), lr=lr, betas=(0.5, 0.999))
optimizerG = torch.optim.Adam(netG.parameters(), lr=lr, betas=(0.5, 0.999))
最后就可以完成网络训练,并使用噪声数据进行测试了。
from torchvision.utils import make_grid
from matplotlib import pyplot as plt
from IPython import display
%matplotlib inline
epochs = 100
for epoch in range(epochs):
for n, (images, _) in enumerate(dataloader):
real_labels = torch.ones(images.size(0))
fake_labels = torch.zeros(images.size(0))
netD.zero_grad()
output = netD(images)
lossD_real = criterion(output.squeeze(), real_labels)
noise = torch.randn(images.size(0), 100, 1, 1)
fake_images = netG(noise)
output2 = netD(fake_images.detach())
lossD_fake = criterion(output2.squeeze(), fake_labels)
lossD = lossD_real + lossD_fake
lossD.backward()
optimizerD.step()
netG.zero_grad()
output3 = netD(fake_images)
lossG = criterion(output3.squeeze(), real_labels)
lossG.backward()
optimizerG.step()
fixed_noise = torch.randn(64, 100, 1, 1)
fixed_images = netG(fixed_noise)
fixed_images = make_grid(fixed_images.data,
nrow=8, normalize=True).cpu()
plt.figure(figsize=(6, 6))
plt.title("Epoch[{}/{}], Batch[{}/{}]".format(epoch+1,
epochs,
n+1,
len(dataloader)))
plt.imshow(fixed_images.permute(1, 2, 0).numpy())
display.display(plt.gcf())
display.clear_output(wait=True)
以下,是迭代 100 个 Epoch 之后的测试结果,可以看到效果还是不错的。
GAN 是近些年来快速发展的网络结构,但由于其模型过于自由,很容易出现训练不收敛,模型崩溃等问题。不过在数据增强,图片生成等方面,GAN 还是有很多的发展空间。未来值得期待。