Multrin:窗口聚合应用

Multrin:窗口聚合应用
Multrin 是一款可用于 Windows 平台的窗口聚合应用,你可以把任意程序拖动到一起,并使用标签页完成快速切换。
Multrin 基于跨平台框架 Electron 构建,但由于其依赖于特定接口,目前还无法在 Mac 或 Linux 上使用。不过,开发者表示正在试图解决此问题,暗色主题也正在开发中。Multrin 开源且免费,Windows 用户现在就可以到 项目页面 下载。
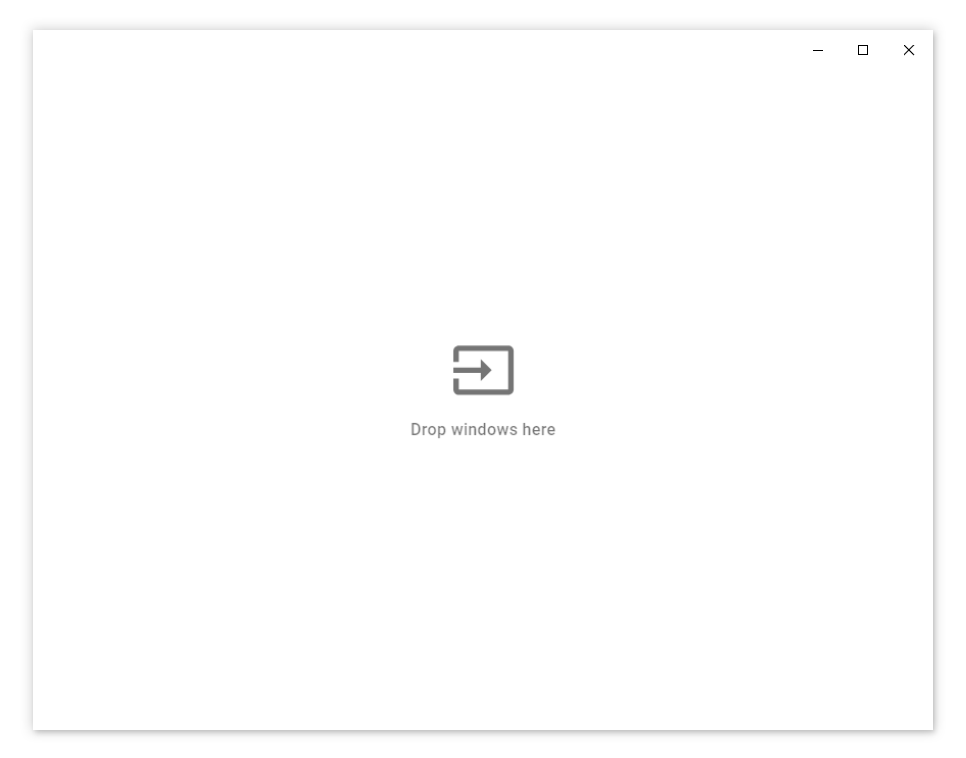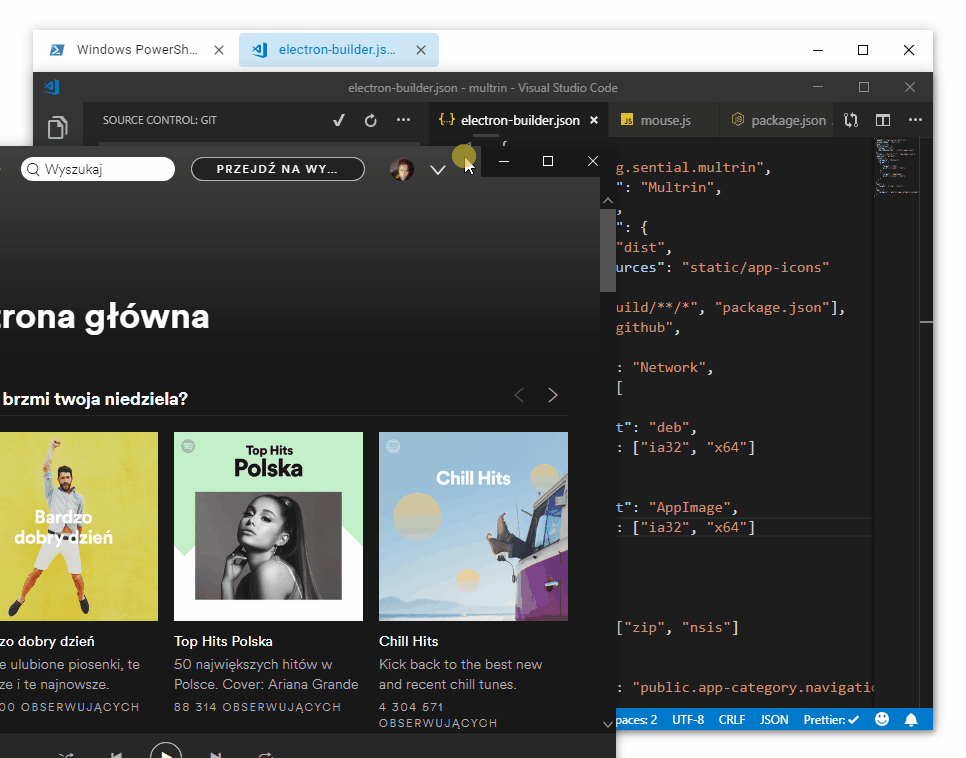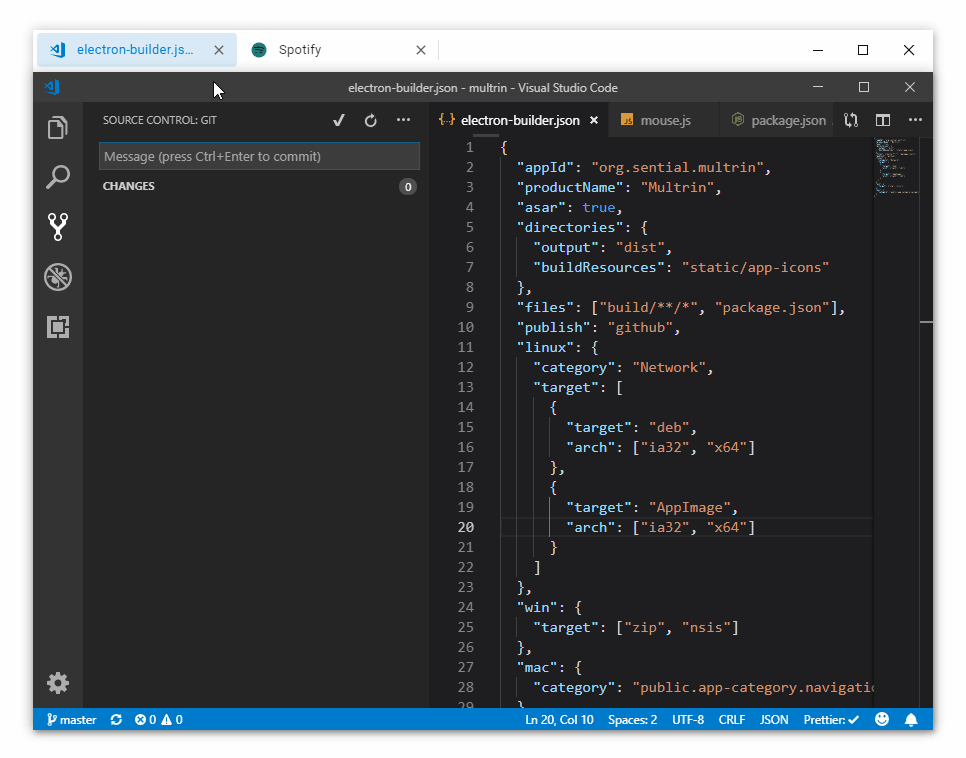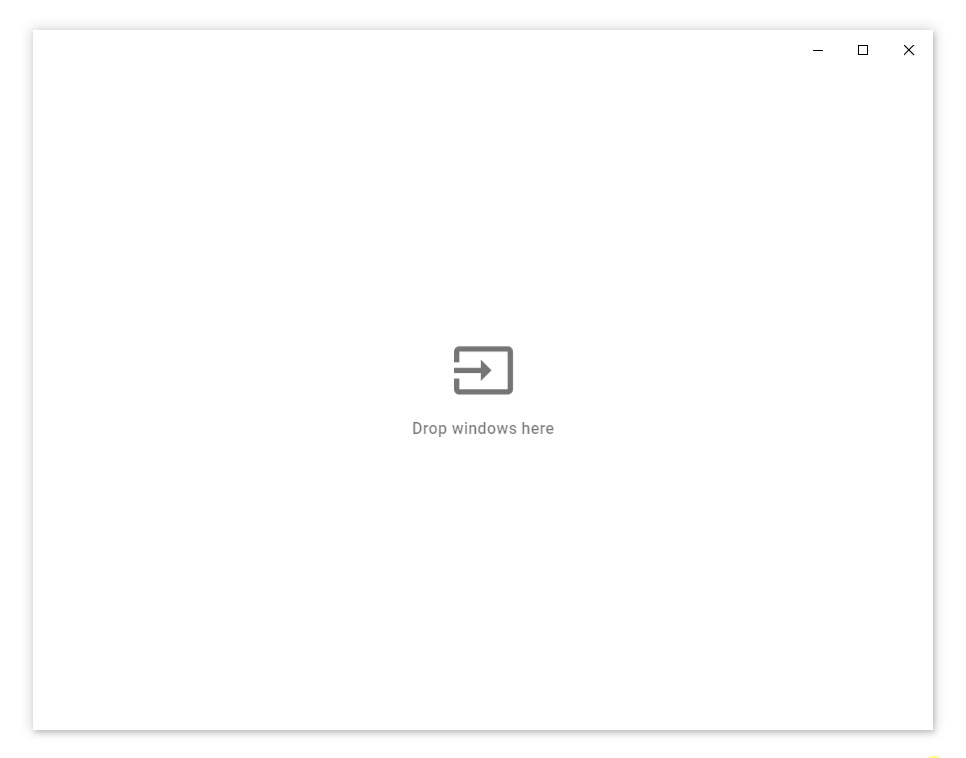

Multrin 是一款可用于 Windows 平台的窗口聚合应用,你可以把任意程序拖动到一起,并使用标签页完成快速切换。
Multrin 基于跨平台框架 Electron 构建,但由于其依赖于特定接口,目前还无法在 Mac 或 Linux 上使用。不过,开发者表示正在试图解决此问题,暗色主题也正在开发中。Multrin 开源且免费,Windows 用户现在就可以到 项目页面 下载。