Spider:提取网页结构化数据

Spider:提取网页结构化数据
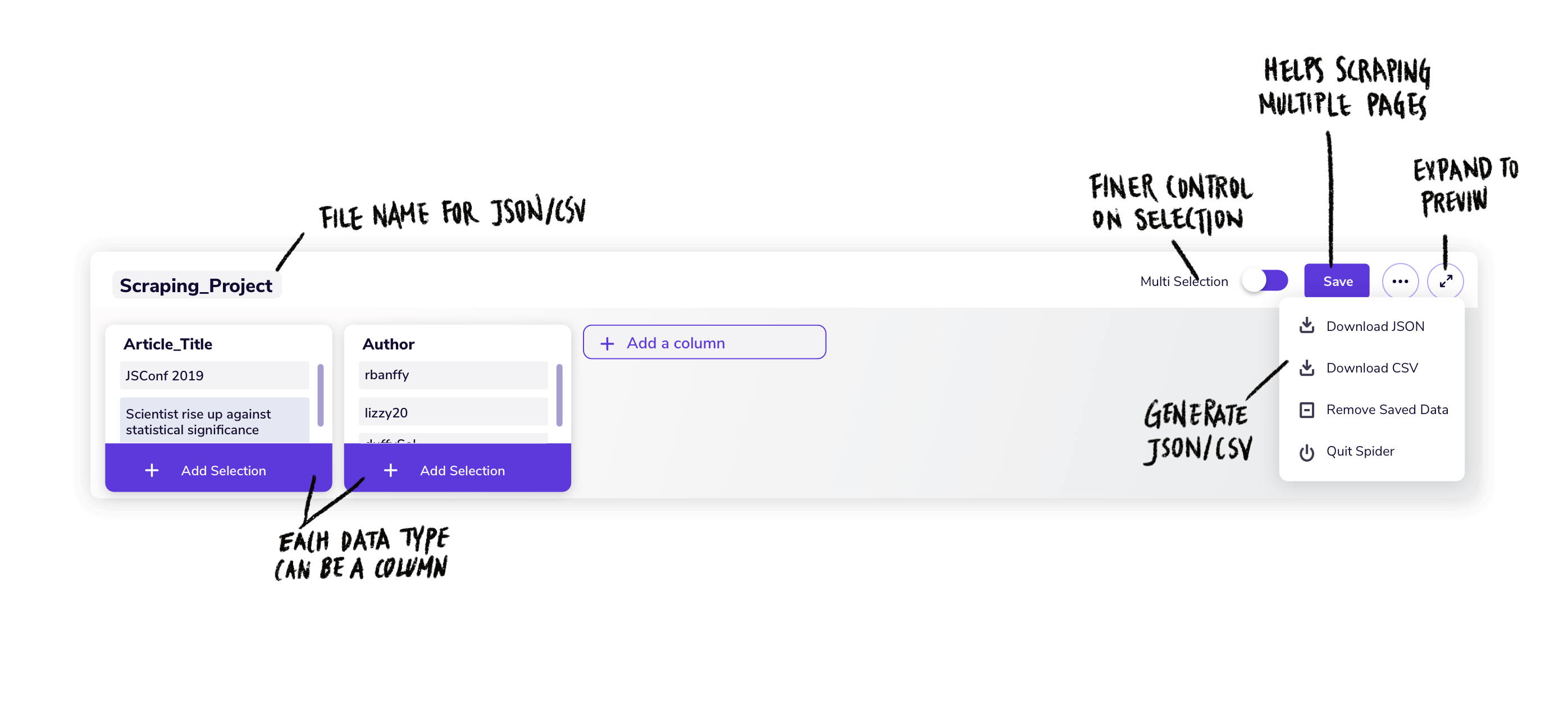
你可能有过这样的需求,从论坛或者商品搜索页面一次性复制全部数据。实际上,在网页构建过程中,为了让信息能规范展示,往往都会使用相同类别的标签去定位标题,正文,题图等组建的样式。于是,借助于这样的思路,Spider 就出现了。
Spider 可以一次性从正在浏览的网页中提取结构化数据,例如复制一整页的商品信息并按标题,售价,销量整理成规范的数据列。实际上这就是网页爬虫的思路,但使用代码写一个数据爬虫对于普通人的门槛太高。Spider 做到了无需编写任何代码,通过鼠标的定位选取就可以将数据导出。
如果你正好有这方面的需要,可以 试一试 Spider。目前,Spider 仅提供的支持 Chrome 浏览器的 拓展程序,其他浏览器拓展正在开发中。