模型推理与部署
介绍
机器学习工程会利用本地训练的模型进行推理,并在有必要的时候将其部署到云端。这篇文章将学会如何对 scikit-learn 构建的模型进行保存,部署和推理。
知识点
- 模型保存
- 模型部署
- 模型推理
到目前为止,相信你已经对机器学习过程非常熟悉。一般情况下,我们会使用训练数据构建模型,然后再用验证数据或测试数据来评估模型。实际上,评估模型的过程在前面也称为预测和评价。
模型推理
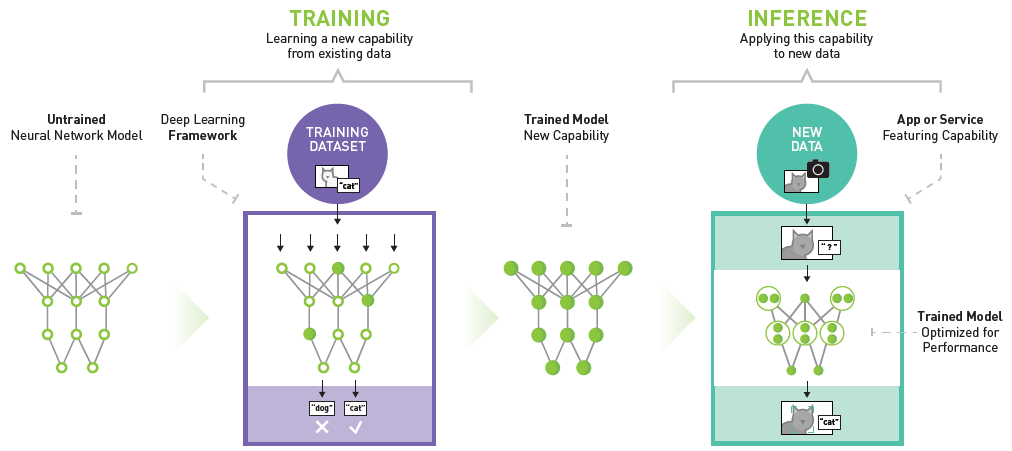
实际上,用训练好的模型对新数据进行预测,在机器学习工程上有一个更专业的名词叫做「推理 Inference」。下图详细说明了神经网络模型训练和推理的过程。通过训练集构建的神经网络对新输入数据进行预测,就是推理。
一般情况下,推理又分为:静态推理与动态推理。
静态推理很好理解,我们通过集中对批量数据进行推理,并将结果存放在数据表或数据库中。当有需要的时候,再直接通过查询来获得推理结果。
而动态推理一般表示我们将模型部署到服务器中。当有需要时,通过向服务器发送请求来获得模型返回的预测结果。与静态推理不同的是,动态推理的过程是实时计算的,而静态推理是提前批量处理好的。
当然,静态和动态推理各有优缺点。静态推理适合于对大批量数据进行处理,因为动态推理面对大数据量时非常耗时。但是静态推理无法实时更新,而动态推理的结果是即时计算结果。
静态推理相信大家都很熟悉了,因为前面的内容中,我们对新数据预测实际上就类似于静态推理的过程。你只需要使用 scikit-learn 提供的 predict 操作即可完成。接下来,我们重点讨论动态推理的过程,并教你使用 RESTful API 的方式部署 scikit-learn 模型并完成动态推理。
模型部署
想要部署 scikit-learn 模型,当然需要先完成模型训练。
下面,我们训练一个泰坦尼克号生存推理模型。数据集通过 seaborn 进行加载,并完成预览。
# 从国内镜像下载 seaborn 数据集避免下一步加载数据集失败
wget -nc "https://labfile.oss.aliyuncs.com/courses/2616/seaborn-data.zip"
!unzip seaborn-data.zip -d ~/
from seaborn import load_dataset
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore') # 忽略模块变动警告
df = load_dataset("titanic") # 加载泰坦尼克数据集
df
可以看的,数据集一共包含 15 列共 891 个样本。我们选择乘客仓位 pclass,性别 sex,登船港口 embarked 等 3 个特征,并使用 alive 是否存活作为目标值。
X = df[["pclass", "sex", "embarked"]] # 特征
y = df["alive"] # 目标
训练之前,我们先对特征数据进行独热编码,独热编码的方法前面已经介绍过了。
X = pd.get_dummies(X) # 独热编码
X.head()
接下来,就可以开始训练了。这里使用随机森林方法建模,并使用交叉验证来查看模型的表现。
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier() # 随机森林
np.mean(cross_val_score(model, X, y, cv=5)) # 5 次交叉验证求平均
交叉验证显示模型的分类准确度大约为 81%。
为了方便模型的部署,我们需要把训练好的模型存储下来。这里可以使用 scikit-learn 提供的 sklearn.externals.joblib,将模型存为 .pkl 二进制文件。保存模型的方法非常简单,直接阅读下面的代码。
from sklearn.externals import joblib
model.fit(X, y) # 训练模型
joblib.dump(model, "titanic.pkl") # 保存模型
现在,有了模型文件,那么就可以部署模型了。我们打算将模型部署到云端(本地测试),这里借助于 Flask 来实现。Flask 是 Python 著名的 Web 应用框架,可以用于构建一个 RESTful API。由于未涉及 Flask 的内容,下面的代码大家需自行结合 官方文档 理解。
%%writefile predict.py
# 将此单元格代码写入 predict.py 文件方便后面执行
from flask import Flask, request, jsonify
from sklearn.externals import joblib
import pandas as pd
app = Flask(__name__)
@app.route("/", methods=["POST"]) # 请求方法为 POST
def predict():
json_ = request.json # 解析请求数据
query_df = pd.DataFrame(json_) # 将 JSON 变为 DataFrame
columns_onehot = ["pclass", "sex_female", "sex_male",
"embarked_C", "embarked_Q", "embarked_S"] # 独热编码 DataFrame 列名
query = pd.get_dummies(query_df).reindex(
columns=columns_onehot, fill_value=0) # 将请求数据 DataFrame 处理成独热编码样式
clf = joblib.load("titanic.pkl") # 加载模型
prediction = clf.predict(query) # 模型推理
return jsonify({"prediction": list(prediction)}) # 返回推理结果
下面,我们详细说明单元格代码的作用和含义。首先,这里通过 Flask 创建的 app 可以通过 HTTP 方法中的 POST 来向服务端发送新数据并返回推理结果。我们定义新数据以 JSON 格式发送,并可以同时发送多条。
上面代码中有一段是将新数据处理成独热编码的样式可能会造成疑惑,接下来会详细讲解。首先,我们定义一组待推理的新数据,注意为 JSON 格式。
import json
# 待推理新数据
sample = [{"pclass": 1, "sex": "male", "embarked": "C"},
{"pclass": 2, "sex": "female", "embarked": "S"}]
# 将 JSON 读取为 DataFrame
sample_df = pd.read_json(json.dumps(sample))
sample_df
请注意,如上所述我们读取到的待推理新数据只有 3 列,而 titanic.pkl 是通过上文 6 列独热编码后的数据训练而来的。如果我们直接传入新数据推理,模型自然会报错。所以,我们需要将新数据处理成与训练数据一致的格式,这就是 Flask 代码中需要对数据独热编码的原因。
# 根据训练数据格式将新数据处理成一致的独热编码格式
pd.get_dummies(sample_df).reindex(columns=X.columns, fill_value=0)
可以看的,通过相应代码处理就能将新数据变成与训练数据一致的独热编码格式,这样就可以使用保存的 titanic.pkl 进行推理了。
下面,我们可以启动 Flask 应用,由于 Jupyter Notebook 环境的限制,此处只能通过子进程的方式启动 Flask,否则无法在 Jupyter Notebook 后面请求 API。此段代码在本地操作和实际部署时不需要,只是为了教学演示顺利进行。
import subprocess as sp
# 启动子进程执行 Flask app
server = sp.Popen("FLASK_APP=predict.py flask run", shell=True)
server
目前,我们的 Flask 应该已经运行起来了,由于使用子进程执行看不到标准输出结果。实际上,应用运行的默认本地链接和端口为 http://127.0.0.1:5000。
接下来,我们就可以使用 HTTP POST 来对新数据进行动态推理了。
import requests
requests.post(url="http://127.0.0.1:5000",
json=sample).content # 建立 POST 请求,并发送新数据
如无意外,你应该能看到 {"prediction":["no","yes"]} 的返回结果,代表示例样本预测结果分别为 no 未幸存和 yes 幸存。
server.terminate() # 结束子进程,关闭端口占用
那么,如果你把上面的 Flask 部署到云端,就完成了服务器动态推理模型部署。
这里,我们给出示例模型部署在云端的测试地址:https://titanic-demo.onrender.com,你可以直接获得测试结果:
# 向服务器发送请求获得预测结果
sample = [{"pclass": 1, "sex": "male", "embarked": "C"},
{"pclass": 2, "sex": "female", "embarked": "S"},
{"pclass": 3, "sex": "male", "embarked": "Q"},
{"pclass": 3, "sex": "female", "embarked": "S"}]
# 稍等片刻,Render 线上服务存在冷却启动时间
requests.post(url="https://titanic-demo.onrender.com", json=sample).content
你可以阅读并参考该项目的 源代码。
小结
这篇文章介绍了 scikit-learn 模型的保存,部署与动态推理。由于涉及到 Flask 的使用,部分知识需要学员额外自行补充学习。不过,相信你从内容中已经能够体会完整的过程。实际上,随着云技术的发展,线上部署模型变得更加方便,类似于 Google Cloud 推出的云端函数或者 AWS Lambda 功能,都能够在无服务器情况下实现机器学习模型快速部署,有兴趣可以自行搜索学习。
系列文章
- 综述及示例
- 线性回归实现与应用
- 多项式回归实现与应用
- 岭回归和 LASSO 回归实现
- 回归模型评价与检验
- 逻辑回归实现与应用
- K-近邻算法实现与应用
- 朴素贝叶斯实现及应用
- 分类模型评价方法
- 支持向量机实现与应用
- 决策树实现与应用
- 装袋和提升集成学习方法
- 划分聚类方法实现与应用
- 层次聚类方法实现与应用
- 主成分分析原理及应用
- 密度聚类方法实现与应用
- 谱聚类及其他聚类方法应用
- 自动化机器学习综述
- 自动化机器学习实践应用
- 模型动态增量训练
- 模型推理与部署
如果你觉得这篇文章对你有帮助,欢迎通过 微信赞赏码 或者 Buy Me a Coffee 请我喝杯咖啡,谢谢!