线性回归最小二乘法与梯度下降法数学推导及 Python 实现

线性回归是一种十分基础的机器学习算法。但是基础并不意味着不重要,相反,基础往往才是最重要的。很多人入门机器学习,第一个学习的就是线性回归。例如,吴恩达的机器学习课程中,也是以线性回归开始。
对于一个线性回归问题,一般来讲有 2 种解决方法,分别是:最小二乘法和梯度下降法。其中最小二乘法又分为两种求解思路:代数求解和矩阵求解。
接下来,我将梳理线性回归问题的求解过程,以及使用 Python 进行编程实现的完整过程。
最小二乘法代数求解推导
最小二乘法是线性回归问题最常用的解决方法。我们这里使用到的是普通最小二乘法,英文为:Ordinary Least Squares,简称 OLS。最小二乘法中的「二乘」代表平方,最小二乘也就是最小平方。而这里的平方就是指代平方损失函数。首先,假设我们需要求解的是一元线性回归问题,及其对应的线性方程如下:

简单来讲,最小二乘法也就是求解平方损失函数最小值的方法。那么,到底该怎样求解呢?这就需要使用到高等数学中的知识。推导如下。
我们所知,平方损失函数的公式为:

由于最终的目标是求取平方损失函数 $min(f)$ 最小时对应的 $w$。所以,先求 $f$ 的一阶偏导数:

然后,我们令 $\frac{\partial f}{\partial w_{0}}=0$ 以及 $\frac{\partial f}{\partial w_{1}}=0$,解得:

至此,我们就用代数的方式求解出线性方程的参数了。其中,$w_0$ 经常习惯称之为截距项。
最小二乘法代数求解实现
接下来,我们依据上面的推导过程,使用 Python 进行实现。这里,假设进行线性拟合的数据如下:
x = [55, 71, 68, 87, 101, 87, 75, 78, 93, 73]
y = [91, 101, 87, 109, 129, 98, 95, 101, 104, 93]
然后,根据公式实现参数计算函数 ols_algebra(x, y):
def ols_algebra(x, y):
n = len(x)
w1 = (n*sum(x*y) - sum(x)*sum(y))/(n*sum(x*x) - sum(x)*sum(x))
w0 = (sum(x*x)*sum(y) - sum(x)*sum(x*y))/(n*sum(x*x)-sum(x)*sum(x))
return w0, w1
最后,就可以得到拟合后的参数值。
import numpy as np
ols_algebra(np.array(x), np.array(y))
>>> (44.25604341391219, 0.7175629008386778)
那么,所对应的线性方程为:$y = 0.718 * x + 44.256$。
最小二乘法矩阵求解推导
除了上面的代数推导过程。通常在实际情况中,更多会使用矩阵的方式来求线性拟合参数。因为在大规模运算中,矩阵的计算效率更高。
矩阵的推导会稍微复杂一些。同样,根据一元线性函数的表达式 $ y(x, w) = w_0 + w_1x$。那么,转换成矩阵形式为:

即:

然后,平方损失函数转换为矩阵形式:

此时,对矩阵求偏导数得到:

当矩阵 $X^TX$ 满秩(不满秩无法通过 OLS 方法求解)时,$(X^TX)^{-1}X^TX=E$,且 $EW=W$。所以,$(X^TX)^{-1}X^TXW=(X^TX)^{-1}X^Ty$。最终得到:

以上,我们完成了线性回归矩阵求解推导。
最小二乘法矩阵求解实现
使用矩阵方法求解时的代码实现过程会更加简单,因为最终参数的求解就只有一个公式。实现 ols_matrix(x, y) 函数如下:
def ols_matrix(x, y):
w = (x.T * x).I * x.T * y
return w
同样,这里使用上面提供的示例数据。注意,由于是矩阵运算,所以需要对原数据进行形状变换,并添加截距项系数 1,否则会因为形状问题无法计算。
x = np.array(x).reshape(len(x), 1)
x = np.concatenate((np.ones_like(x), x), axis=1)
x = np.matrix(x)
y = np.array(y).reshape(len(y), 1)
y = np.matrix(y)
ols_matrix(x, y)
>>> matrix([[44.25604341], [ 0.7175629 ]])
可以看到,这里得到的结果与代数求解方法一致。
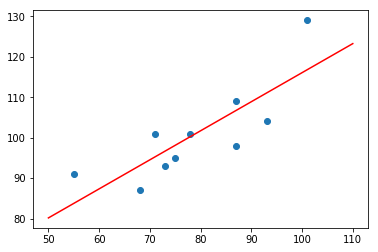
上面我们使用最小二乘法来求解线性方程系数,得到的结果是精确的解析解。最后,尝试将拟合的直线绘制成图,查看拟合效果。这里,四舍五入保留参数的 3 为小数。
$$y = 44.256 + 0.718 * x$$
import matplotlib.pyplot as plt
plt.scatter(x, y)
plt.plot(np.array([50, 110]), np.array([50, 110]) * 0.718 + 44.256, 'r')
梯度下降法求解数学推导
介绍完最小二乘法,下面来说一说梯度下降法的求解过程,关于梯度下降法的原理和过程这里不再解释。梯度下降法作为迭代优化方法,需要提前定义好损失函数。这里选择均方误差 MSE 作为损失函数。

其中,$y_{i}$ 表示真实值,$\hat y_{i}$ 表示近似值,$n$ 则表示值的个数。近似值则通过当前已知计算,那么:

此时,我们求解参数和截距项对应的梯度:

那么,根据梯度就可以执行迭代更新,从而找到最优参数:

梯度下降法求解代码实现
相比于前面的最小二乘法实现过程,梯度下降法的 Python 实现会稍微麻烦一些。不过通过上面的公式,我们也能很快地完成代码编写:
def gradient_descent(x, y, lr, num_iter):
w1 = 0 # 初始参数为 0
w0 = 0 # 初始参数为 0
for i in range(num_iter): # 梯度下降迭代
# 计算近似值
y_hat = (w1 * x) + w0
# 计算参数对应梯度
w1_gradient = -(2/len(x)) * sum(x * (y - y_hat))
w0_gradient = -(2/len(x)) * sum(y - y_hat)
# 根据梯度更新参数
w1 -= lr * w1_gradient
w0 -= lr * w0_gradient
return w1, w0
同样,使用上面的示例数据完成参数计算:
w1, w0 = gradient_descent(np.array(x), np.array(y), lr=0.00001, num_iter=100)
w1, w0
>>> (1.264673601681181, 0.017892580143733863)
因为是迭代方法,所以需要设置学习率和最大迭代次数。你可能发现,这里得到的结果与最小二乘法不太一致,这是不同方法带来的普遍现象。同样绘制出拟合直线:
plt.scatter(x, y)
plt.plot(np.array([50, 110]), np.array([50, 110]) * w1 + w0, 'r')
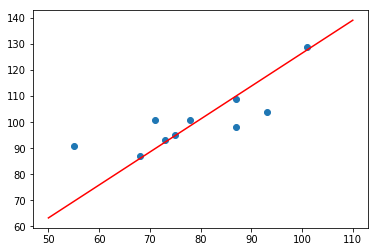
肉眼可见,最终的拟合情况不如最小二乘法。当然,如果随机初始参数以及调整合适的迭代次数及学习率,优化迭代结果可能会更理想一些。
小结
本文系统地介绍了线性回归问题的两种不同的求解方法,分别是:最小二乘法和梯度下降法。同时,对 3 种求解过程进行了编程实现,希望对机器学习初学者带来启发。如何有相关疑问,欢迎交流探讨。
关联推荐
如果你觉得这篇文章对你有帮助,欢迎通过 微信赞赏码 或者 Buy Me a Coffee 请我喝杯 ☕️