感知机和人工神经网络

介绍
人工神经网络是一种发展时间较早且十分常用的机器学习算法。因其模仿人类神经元工作的特点,在监督学习和非监督学习领域都给予了人工神经网络较高的期望。目前,由传统人工神经网络发展而来的卷积神经网络、循环神经网络已经成为了深度学习的基石。这篇文章中,我们将从人工神经网络的原型感知机出发,介绍机器学习中人工神经网络的特点及应用。
知识点
- 感知机的推导过程
- 随机梯度下降法
- 多层感知机与人工神经网络
- 反向传播算法
- 实现人工神经网络
感知机
这篇文章的重点在于人工神经网络。但是,在介绍人工神经网络之前,我们先介绍它的原型:感知机。关于感知机,我们先引用一段来自维基百科的背景介绍:
感知器(英语:Perceptron)是 Frank Rosenblatt 在 1957 年就职于 Cornell 航空实验室时所发明的一种人工神经网络。它可以被视为一种最简单形式的前馈神经网络,是一种二元线性分类器。
如果你之前从未接触过人工神经网络,那么上面这句话或许还需要等到这篇文章结束才能完整理解。不过,你可以初步发现,感知机其实就是人工神经网络,只不过是其初级形态。
感知机的推导过程
那么,感知机到底是什么?它是怎样被发明出来的呢?
要搞清楚上面的问题,我们就需要提到前面学习过的一个非常熟悉的知识点:线性回归。回忆逻辑回归实验的内容,你应该还能记得当初我们说过逻辑回归起源于线性回归。而感知机作为一种最简单的二分类模型,它其实就是使用了线性回归的方法完成平面数据点的分类。而逻辑回归后面引入了逻辑斯蒂估计来计算分类概率的方法甚至可以被当作是感知机的进步。
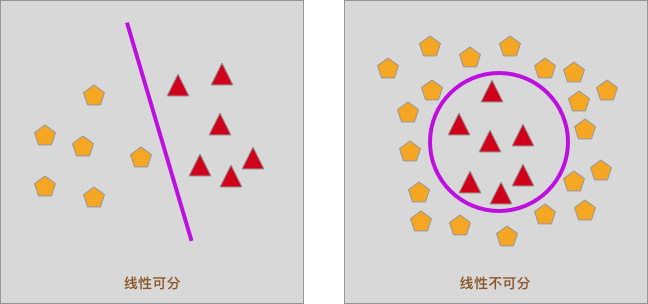
你还记得上面这张图片吗?当数据点处于线性可分时,我们可以使用一条直线将其分开,而分割线的函数为:
对于公式 $(1)$ 而言,我们可以认为分割直线方程其实就是针对数据集的每一个特征 $x_{1}, x_{2}, \cdots, x_{n}$ 依次乘上权重 $w_{1}, w_{2}, \cdots, w_{n}$ 所得。
当我们确定好公式 $(1)$ 的参数后,每次输入一个数据点对应的特征 $x_{1}, x_{2}, \cdots, x_{n}$ 就能得到对应的函数值 $f(x)$ 。那么,怎样判定这个数据点属于哪一个类别呢?
在二分类问题中,我们最终的类别共有两个,通常被称之为正类别和负类别。而当我们使用线性回归中对应的公式 $(1)$ 完成分类时,不同于逻辑回归中将 $f(x)$ 传入 sigmoid 函数,这里我们将 $f(x)$ 传入如下所示的 Sign 函数。
Sign 函数又被称之为符号函数,它的函数值只有 2 个。即当自变量 $x \geq 0$ 时,因变量为 1。同理,当 $x < 0$ 时,因变量为 -1。函数图像如下:

于是,当我们将公式 $(1)$ 中的 $f(x)$ 传入公式 $(2)$ ,就能得到 $sign( f(x) )$ 的值。其中,当 $sign( f(x) ) = 1$ 时,就为正分类点,而 $sign(f(x)) = -1$ 时,则为负分类点。
综上所示,我们就假设输入空间(特征向量)为 $X \subseteq R^n$,输出空间为 $Y={-1, +1}$。输入 $x \subseteq X$ 表示实例的特征向量,对应于输入空间的点;输出 $y \subseteq Y$ 表示示例的类别。由输入空间到输出空间的函数如下:
公式 $(3)$ 就被称之为感知机。注意,公式 $(3)$ 中的 $f(x)$ 和公式 $(1)$ 中的 $f(x)$ 不是同一个 $f(x)$ 。
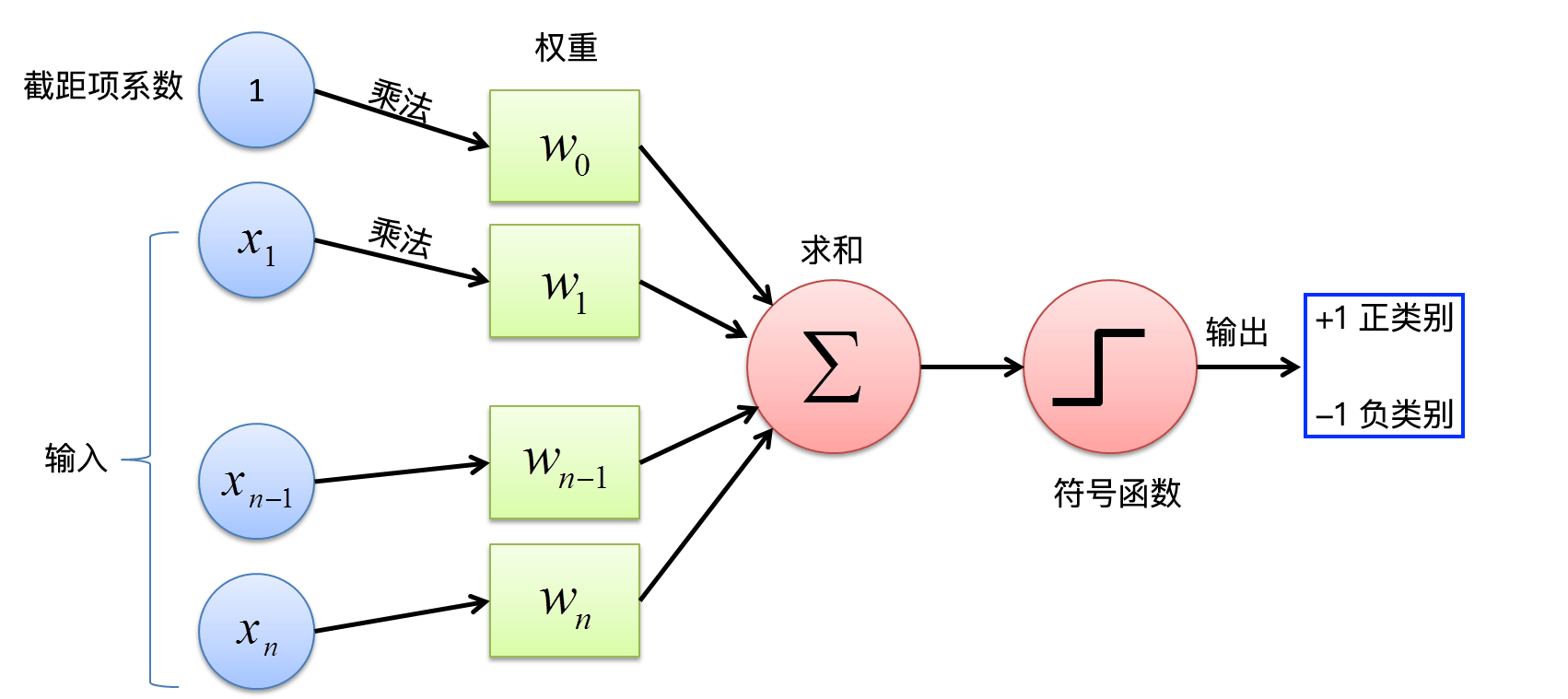
感知机计算流程图
上面,我们针对感知机进行了数学推导。为了更加清晰地展示出感知机的计算过程,我们将其绘制成如下所示的流程图。
感知机的损失函数
前面的实验中,我们已经介绍过损失函数的定义。在感知机的学习过程中,我们同样需要确定每一个特征变量对应的参数,而损失函数的极小值往往就意味着参数最佳。那么,感知机学习的策略,也就是其通常采用哪种形式的损失函数呢?
如下图所示,当我们使用一条直线去分隔一个线性可分的数据集时,有可能会出现「误分类」的状况。
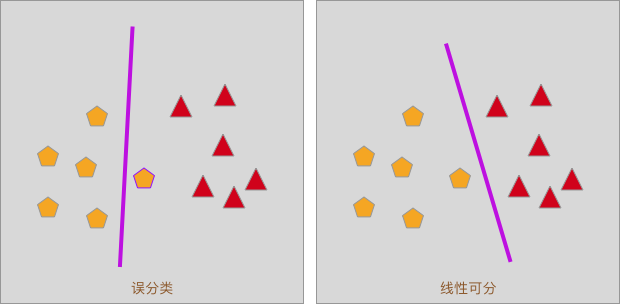
而在感知机的学习过程中,我们通常会使用误分类点到分割线(面)的距离去定义损失函数。
点到直线的距离
中学阶段,我们学过点到直线的距离公式推导。对于 $n$ 维实数向量空间中任意一点 $x_0$ 到直线 $W*x+b=0$ 的距离为:
其中 $||W||$ 表示 $L_2$ 范数,即向量各元素的平方和然后开方。
对于点 $(x_i,y_i)$,使用公式 $(3)$ 进行分类时,如果 $Wx_i+b>0$,则 $sign(Wx_i+b)=1$。那么,此点的预测分类为 $+1$,反之预测分类为 $-1$。
如果此点的真实分类与预测分类不同,则称为误分类点。对于误分类点,真实的 $y_i = +1$,但使用感知机算出来的 $W x_i + b < 0$;或者真实的 $y_i = -1$,但使用感知机算出来的 $W x_i + b > 0$。这两种情况下 $y_i(W * x_{i}+ b) < 0$ 均成立,即对于误分类点,公式 $(5)$ 成立。
$$
- y_i(W * x_{i}+b)>0 \tag{5}
d=-\dfrac{1}{\parallel W\parallel}y_i(W*x_{i}+b) \tag{6}
-\dfrac{1}{\parallel W\parallel}\sum_{x_i\epsilon M} y_i(W*x_{i}+b) \tag{7}
J(W,b) = - \sum_{x_i\epsilon M} y_i(W*x_{i}+b) \tag{8}
$$
从公式 $(8)$ 可以看出,损失函数 $J(W,b)$ 是非负的。也就是说,当没有误分类点时,损失函数的值为 0。同时,误分类点越少,误分类点距离分割线(面)就越近,损失函数值就越小。同时,损失函数 $J(W,b)$ 是连续可导函数。
随机梯度下降法
当我们在实现分类时,最终想要的结果肯定是没有误分类的点,也就是损失函数取极小值时的结果。在逻辑回归的实验中,为了找到损失函数的极小值,我们使用到了一种叫做梯度下降法(Gradient Descent)。而在今天的实验中,我们尝试一种梯度下降法的改进方法,也称之为随机梯度下降法(Stochastic Gradient Descent,简称:SGD)。
使用 SGD 计算公式 $(8)$ 的极小值时,首先任选一个分割面 $W_0$ 和 $b_0$,然后使用梯度下降法不断地极小化损失函数:
随机梯度下降的特点在于,极小化过程中不是一次针对 $M$ 中的所有误分类点执行梯度下降,而是每次随机选取一个误分类点执行梯度下降。等到更新完 $W$ 和 $b$ 之后,下一次再另随机选择一个误分类点执行梯度下降直到收敛。
计算损失函数的偏导数:
如果 $y_i(W * x_{i}+b)\leq0$ 更新 $W$ 和 $b$ :
同前面的梯度下降一致,$\lambda$ 为学习率,也就是每次梯度下降的步长。下面,我们使用 Python 将上面的随机梯度下降算法进行实现。
from sklearn.utils import shuffle
def perceptron_sgd(X, Y, alpha, epochs):
"""
参数:
X -- 自变量数据矩阵
Y -- 因变量数据矩阵
alpha -- lamda 参数
epochs -- 迭代次数
返回:
w -- 权重系数
b -- 截距项
"""
# 感知机随机梯度下降算法实现
w = np.zeros(len(X[0])) # 初始化参数为 0
b = np.zeros(1)
for t in range(epochs): # 迭代
# 每一次迭代循环打乱训练样本
# X, Y = shuffle(X, Y)
for i, x in enumerate(X):
if ((np.dot(X[i], w)+b)*Y[i]) <= 0: # 判断条件
w = w + alpha*X[i]*Y[i] # 更新参数
b = b + alpha*Y[i]
return w, b
小贴士
理论上讲,随机梯度下降计算过程中,每一次迭代更新都需要随机打乱样本数据。但为了便于控制后续内容输出的唯一性,方便内容讲解,上面的实现中注释了相关代码。你可以再学完内容后,取消注释重新执行。
随机梯度下降方法是一项伟大的发明,由于深度学习解决问题面临的数据集都非常大,传统的梯度下降在全数据集上计算效率低。但 SGD 每次只计算一个样本,所以其计算速度非常快并且适合线上更新模型。
当然,由于 SGD 针对单样本更新,也很容易导致损失变化震荡,且有可能无法达到最优点。例如下面这张通过 SGD 优化使得目标函数出现剧烈波动的示意图。
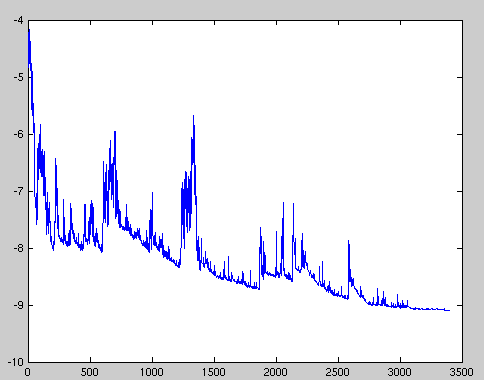
不过,这种震荡波动也有一定好处。其中,与梯度下降法在非凸函数上收敛会使得损失函数陷入局部最小相比,SGD 的震荡波动可能使得其跳到新的和潜在更好的局部最优。所以在实际应用时,随机梯度下降也更为常用。
除了梯度下降法和随机梯度下降法,还有一种小批量梯度下降。小批量梯度下降法在每次更新时使用小批量训练样本,可以看作是梯度下降和随机梯度下降的折中方案,我们在这里就不再赘述了。
感知机分类实例
前面的内容中,我们讨论了感知机的计算流程,感知机的损失函数,以及如何使用随机梯度下降求解感知机的参数。理论说了这么多,下面就举一个实际的例子看一看。
示例数据集
为了方便绘图到二维平面,这里只使用包含两个特征变量的数据,数据集名称为 course-12-data.csv。首先,加载示例数据。
import pandas as pd
df = pd.read_csv(
"https://labfile.oss.aliyuncs.com/courses/1081/course-12-data.csv", header=0) # 加载数据集
df.head() # 预览前 5 行数据
可以看到,该数据集共有两个特征变量 X0 和 X1, 以及一个目标值 Y。其中,目标值 Y 只包含 -1 和 1。我们尝试将该数据集绘制成图,看一看数据的分布情况。
from matplotlib import pyplot as plt
%matplotlib inline
# 绘制数据集
plt.figure(figsize=(10, 6))
plt.scatter(df['X0'], df['X1'], c=df['Y'])
感知机训练
接下来,我们就使用感知机求解最佳分割线。
import numpy as np
X = df[['X0', 'X1']].values
Y = df['Y'].values
alpha = 0.1
epochs = 150
perceptron_sgd(X, Y, alpha, epochs)
于是,我们求得的最佳分割线方程为:
此时,可以求解一下分类的正确率:
L = perceptron_sgd(X, Y, alpha, epochs)
w1 = L[0][0]
w2 = L[0][1]
b = L[1]
z = np.dot(X, np.array([w1, w2]).T) + b
np.sign(z)
为了方便,我们就直接使用 scikit-learn 提供的准确率计算方法 accuracy_score(),该方法相信你已经非常熟悉了
from sklearn.metrics import accuracy_score
accuracy_score(Y, np.sign(z))
所以,最终的分类准确率约为 0.987。
绘制决策边界线
# 绘制轮廓线图,不需要掌握
plt.figure(figsize=(10, 6))
plt.scatter(df['X0'], df['X1'], c=df['Y'])
x1_min, x1_max = df['X0'].min(), df['X0'].max(),
x2_min, x2_max = df['X1'].min(), df['X1'].max(),
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max),
np.linspace(x2_min, x2_max))
grid = np.c_[xx1.ravel(), xx2.ravel()]
probs = (np.dot(grid, np.array(
[L[0][0], L[0][1]]).T) + L[1]).reshape(xx1.shape)
plt.contour(xx1, xx2, probs, [0], linewidths=1, colors='red')
可以看到,上图中的红色直线就是我们最终的分割线,分类的效果还是不错的。
绘制损失函数变换曲线
除了绘制决策边界,也就是分割线。我们也可以将损失函数的变化过程绘制处理,看一看梯度下降的执行过程。
def perceptron_loss(X, Y, alpha, epochs):
"""
参数:
X -- 自变量数据矩阵
Y -- 因变量数据矩阵
alpha -- lamda 参数
epochs -- 迭代次数
返回:
loss_list -- 每次迭代损失函数值列表
"""
# 计算每次迭代后的损失函数值
w = np.zeros(len(X[0])) # 初始化参数为 0
b = np.zeros(1)
loss_list = []
for t in range(epochs): # 迭代
loss_init = 0
for i, x in enumerate(X):
# 每一次迭代循环打乱训练样本
# X, Y = shuffle(X, Y)
if ((np.dot(X[i], w)+b)*Y[i]) <= 0: # 判断条件
loss_init += (((np.dot(X[i], w)+b)*Y[i]))
w = w + alpha*X[i]*Y[i] # 更新参数
b = b + alpha*Y[i]
loss_list.append(loss_init * -1)
return loss_list
loss_list = perceptron_loss(X, Y, alpha, epochs)
plt.figure(figsize=(10, 6))
plt.plot([i for i in range(len(loss_list))], loss_list)
plt.xlabel("Learning rate {}, Epochs {}".format(alpha, epochs))
plt.ylabel("Loss function")
如上图所示,你会发现,让我们按照 0.1 的学习率迭代 150 次后,损失函数依旧无法到达 0。一般情况下,当我们的数据不是线性可分时,损失函数就会出现如上图所示的震荡线性。当然,这其实也体现出了如上所述 SDG 在应用时,目标函数曲线变化的震荡波动。
不过,如果你仔细观察上方数据的散点图,你会发现这个数据集看起来是线性可分的。那么,当数据集线性可分,却造成损失函数变换曲线震荡的原因一般有两点:学习率太大或者迭代次数太少。
其中,迭代次数太少很好理解,也就是说我们迭代的次数还不足以求得极小值。至于学习率太小或太大,可以看下方的示意图。

如上图所示,当我们的学习率太大时,往往容易出现在损失函数底部来回震荡的现象而无法到达极小值点。所以,面对上面这种情况,我们可以采取减小学习率并增加迭代次数的方法找到损失函数极小值点。
所以,下面就再试一次。
alpha = 0.05 # 减小学习率
epochs = 1000 # 增加迭代次数
loss_list = perceptron_loss(X, Y, alpha, epochs)
plt.figure(figsize=(10, 6))
plt.plot([i for i in range(len(loss_list))], loss_list)
plt.xlabel("Learning rate {}, Epochs {}".format(alpha, epochs))
plt.ylabel("Loss function")
可以看到,当迭代次数约为 700 次,即上图后半段时,损失函数的值等于 0。根据我们在前面小节中介绍的内容,当损失函数为 0 时,就代表没有误分类点存在。
此时,我们再一次计算分类准确率。
L = perceptron_sgd(X, Y, alpha, epochs)
z = np.dot(X, L[0].T) + L[1]
accuracy_score(Y, np.sign(z))
和损失函数变化曲线得到的结论一致,分类准确率已经 $100\%$,表示全部数据点被正确分类。
人工神经网络
上面的内容中,我们已经了解到了什么是感知机,以及如何构建一个感知机分类模型。你会发现,感知机只能处理二分类问题,且必须是线性可分问题。如果是这样的话,该方法的局限性就比较大了。那么,面对线性不可分或者多分类问题时,我们有没有一个更好的方法呢?
多层感知机与人工神经网络
这里,就要提到本文的主角,也就是人工神经网络(英语:Artificial Neural Network,简称:ANN)。如果你第一次接触到人工神经网络,不要将其想的太神秘。其实,上面的感知机模型就是一个人工神经网络,只不过它是一个结构简单的单层神经网络。而如果我们要解决线性不可分或者多分类问题,往往会尝试将多个感知机组合在一起,变成一个更复杂的神经网络结构。
小贴士
由于一些历史遗留问题,感知机、多层感知机、人工神经网络三种说法界限模糊,这篇文章中介绍到的人工神经网络从某种意义上代指多层感知机。
上文中,我们通过一张图展示了感知机的工作流程,我们将该流程图进一步精简如下:
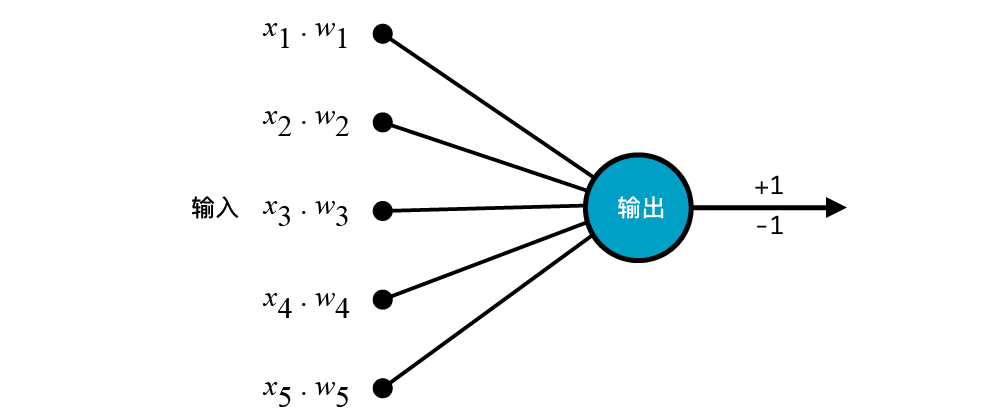
这张图展示了一个感知机模型的执行流程。我们可以把输入称之为「输入层」,输出称之为「输出层」。对于像这样只包含一个输入层的网络结构就可以称之为单层神经网络结构。
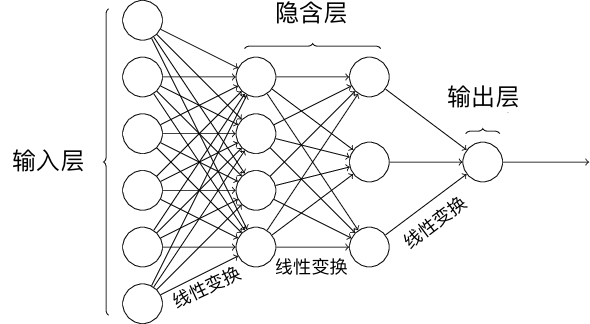
单个感知机组成了单层神经网络,如果我们将一个感知机的输出作为另一个感知机的输入,就组成了多层感知机,也就是一个多层神经网络。其中,我们将输入和输出层之间的称为隐含层。如下图所示,这就是包含 1 个隐含层的神经网络结构。
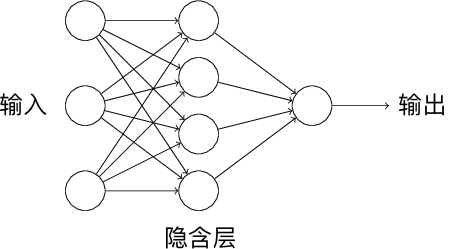
一个神经网络结构在计算层数的时候,我们一般只计算输入和隐含层的数量,即上方是一个 2 层神经网络结构。
激活函数
目前,我们已经接触过逻辑回归、感知机、多层感知机与人工神经网络 4 个概念。你可能隐约感觉到,似乎这 4 种方法都与线性函数有关,而区别在于对线性函数的因变量的不同处理方式上面。
- 对于逻辑回归而言,我们是采用了 $sigmoid$ 函数将 $f(x)$ 转换为概率,最终实现二分类。
- 对于感知机而言,我们是采用了 $sign$ 函数将 $f(x)$ 转换为 -1 和 +1 最终实现二分类。
- 对于多层感知机而言,具有多层神经网络结构,在 $f(x)$ 的处理方式上,一般会有更多的操作。
于是,$sigmoid$ 函数和 $sign$ 函数还有另外一个称谓,叫做「激活函数(Activation function)」。听到激活函数,大家首先不要觉得它有多么的高级。之所以有这样一个称谓,是因为函数本身有一些特点,但归根结底还是数学函数。下面,我们就列举一下常见的激活函数及其图像。
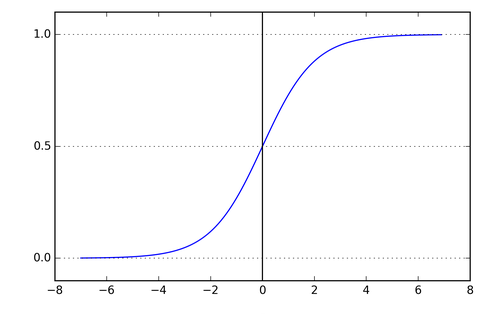
$sigmoid$ 函数
$sigmoid$ 函数应该已经非常熟悉了吧,它的公式如下:
$sigmoid$ 函数的图像呈 S 型,函数值介于 $(0, 1)$ 之间:
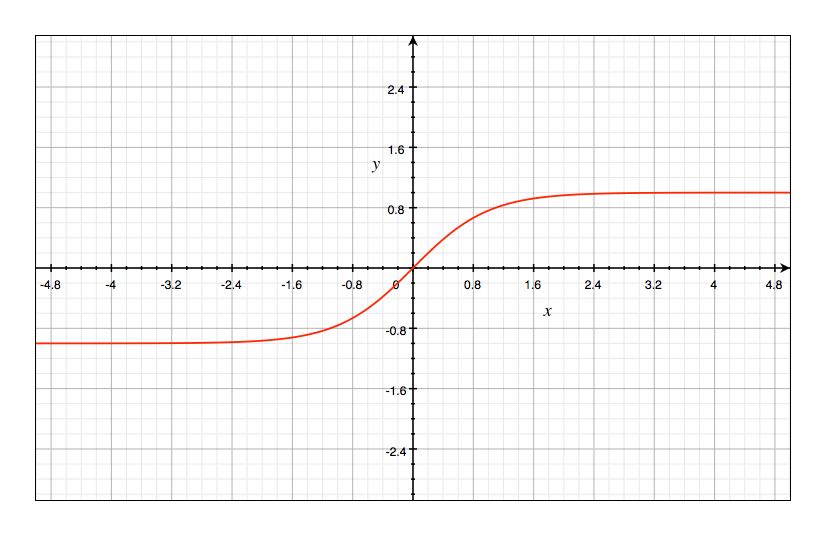
$Tanh$ 函数
$Tanh$ 函数与 $sigmoid$ 函数的图像很相似,都呈 S 型,只不过 $Tanh$ 函数值介于 $(-1, 1)$ 之间,公式如下:
$ReLU$ 函数
$ReLU$ 函数全称叫做 Rectified Linear Unit,也就是修正线性单元,公式如下:
$ReLU$ 有很多优点,比如收敛速度会较快且不容易出现梯度消失。由于这次实验不会用到,我们之后再说。$ReLU$ 的图像如下:
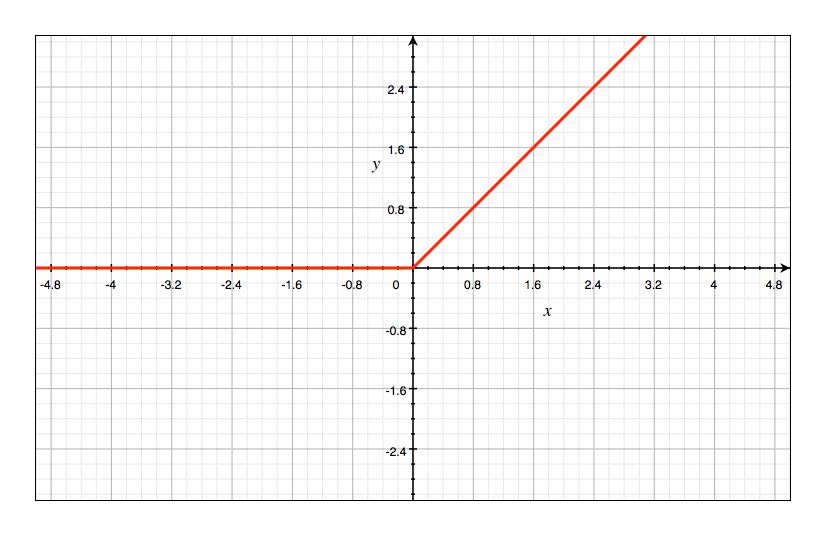
激活函数的作用
上面列举了 3 种常用的激活函数,其中 $sigmoid$ 函数是今天介绍的人工神经网络中十分常用的一种激活函数。谈到激活函数的作用,直白地讲就是针对数据进行非线性变换。只是不同的激活函数适用于不同的场景,而这些都是机器学习专家根据应用经验总结得到的。
在神经网络结构中,我们通过线性函数不断的连接输入和输出。你可以设想,在这种结构中,每一层输出都是上层输入的线性变换。于是,无论神经网络有多少层,最终输出都是输入的线性组合。这样的话,单层神经网络和多层神经网络有什么区别呢?(没有区别)
如上图所示,线性变换的多重组合依旧还是线性变换。如果我们在网络结构中加入激活函数,就相当于引入了非线性因素,这样就可以解决线性模型无法完成的分类任务。
反向传播算法(BP)直观认识
前面感知机的章节中,我们定义了一个损失函数,并通过一种叫做随机梯度下降的方法去求解最优参数。如果你仔细观察随机梯度下降的过程,其实就是通过求解偏导数并组合成梯度用于更新权重 $W$ 和 $b$。感知机只有一层网络结构,求解梯度的过程还比较简单。但是,当我们组合成多层神经网络之后,更新权重的过程就变得复杂起来,而反向传播算法正是为了快速求解梯度而生。
反向传播的算法说起来很简单,但要顺利理解还比较复杂。这里,我们引用了一篇 科普文章 中的配图来帮助理解反向传播的过程。
下图呈现了一个经典的 3 层神经网络结构,其包含有 2 个输入 $x_{1}$ 和 $x_{2}$ 以及 1 个输出 $y$。
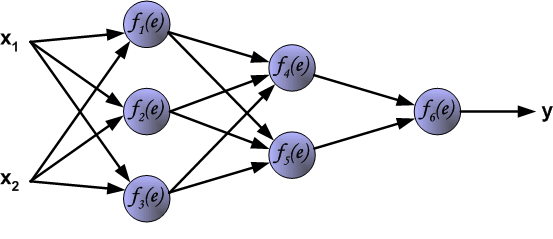
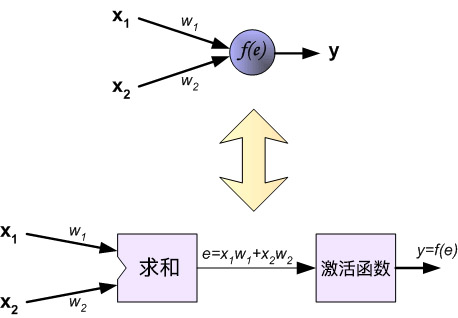
网络中的每个紫色单元代表一个独立的神经元,它分别由两个单元组成。一个单元是权重和输入信号,而另一个则是上面提到的激活函数。其中,$e$ 代表激活信号,所以 $y = f(e)$ 就是被激活函数处理之后的非线性输出,也就是整个神经元的输出。
下面开始训练神经网络,训练数据由输入信号 $x_{1}$ 和 $x_{2}$ 以及期望输出 $z$ 组成,首先计算第 1 个隐含层中第 1 个神经元 $y_{1} = f_{1}(e)$ 对应的值。
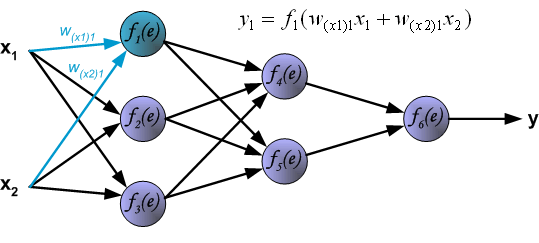
接下来,计算第 1 个隐含层中第 2 个神经元 $y_{2} = f_{2}(e)$ 对应的值。
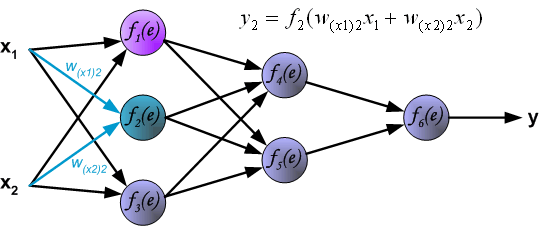
然后是计算第 1 个隐含层中第 3 个神经元 $y_{3} = f_{3}(e)$ 对应的值。
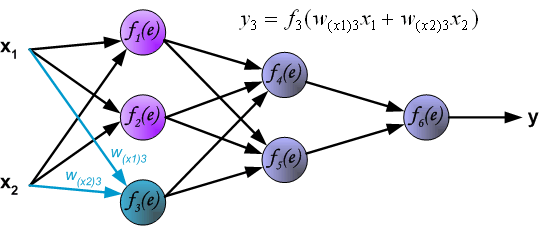
与计算第 1 个隐含层的过程相似,我们可以计算第 2 个隐含层的数值。
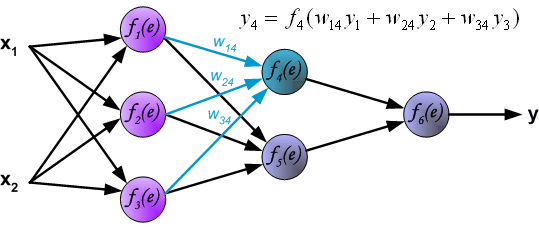
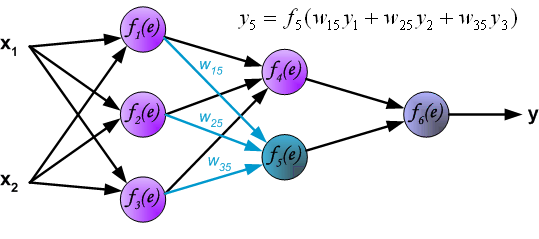
最后,得到输出层的结果:
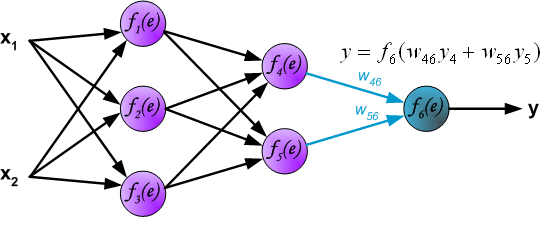
上面这个过程被称为前向传播过程,那什么是反向传播呢?接着来看:
当我们得到输出结果 $y$ 时,可以与期望输出 $z$ 对比得到误差 $\delta$。
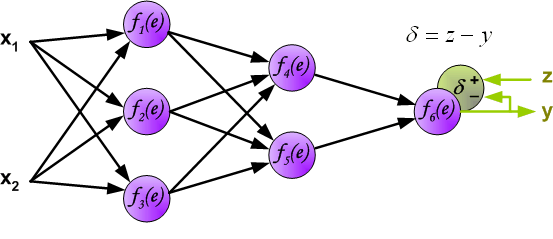
然后,我们将计算得到的误差 $\delta$ 沿着神经元回路反向传递到前 1 个隐含层,而每个神经元对应的误差为传递过来的误差乘以权重。
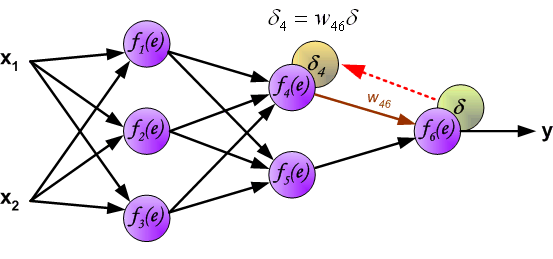
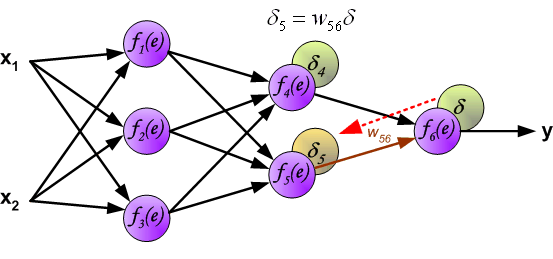
同理,我们将第 2 个隐含层的误差继续向第 1 个隐含层反向传递。
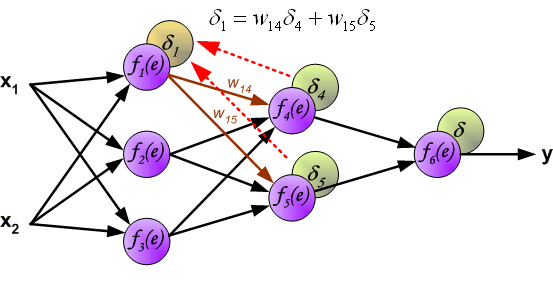
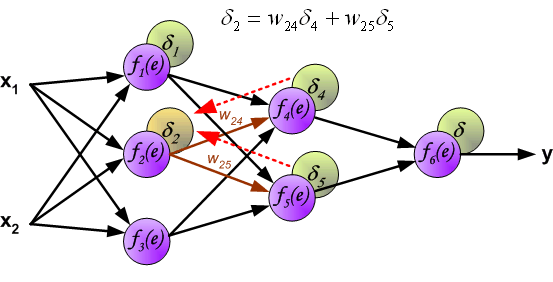
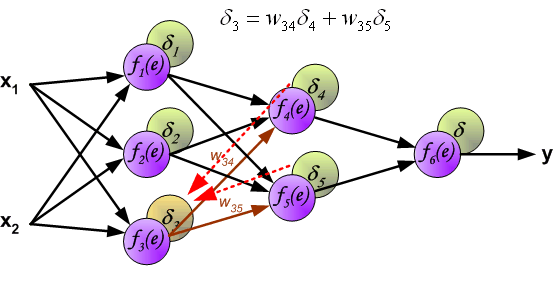
此时,我们就可以利用反向传递过来的误差对从输入层到第 1 个隐含层之间的权值 $w$ 进行更新,如下图所示:
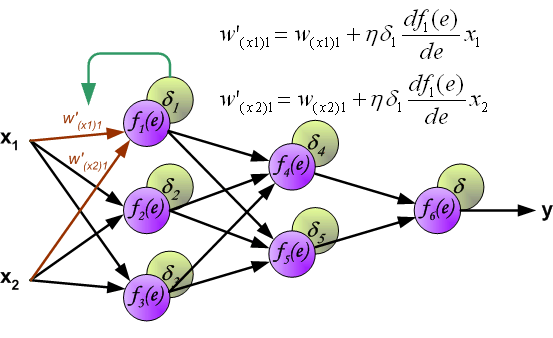
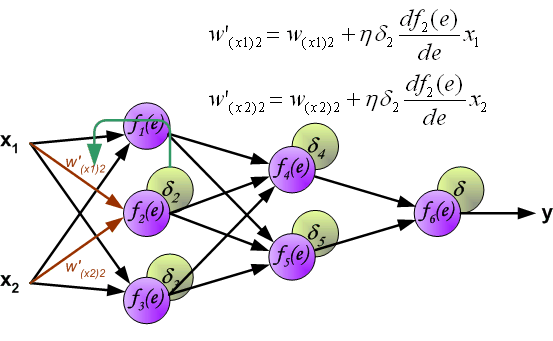
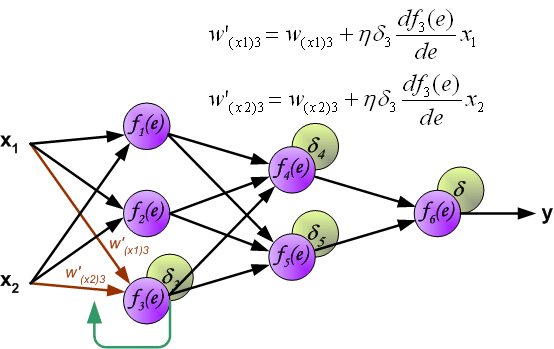
同样,对第 1 个隐含层与第 2 个隐含层之间的权值 $w$ 进行更新,如下图所示:
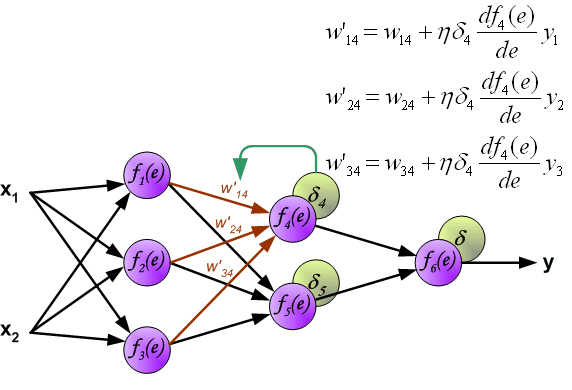
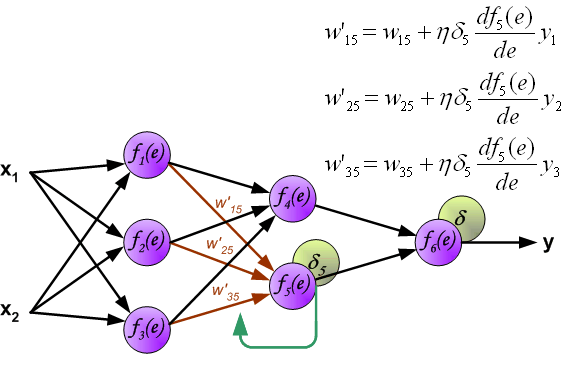
最后,更新第 2 个隐含层与输出层之间的权值 $w$ ,如下图所示:
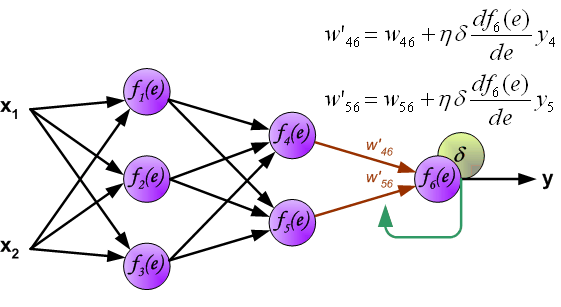
图中的 $\eta$ 表示学习速率。这就完成了一个迭代过程。更新完权重之后,又开始下一轮的前向传播得到输出,再反向传播误差更新权重,依次迭代下去。
所以,反向传播其实代表的是反向传播误差。
Python 实现人工神经网络
上面的内容,我们介绍了人工神经网络的构成和最重要的反向传播算法。接下来,尝试通过 Python 来实现一个神经网络运行的完整流程。
定义神经网络结构
为了让推导过程足够清晰,这里我们只构建包含 1 个隐含层的人工神经网络结构。其中,输入层为 2 个神经元,隐含层为 3 个神经元,并通过输出层实现 2 分类问题的求解。该神经网络的结构如下:
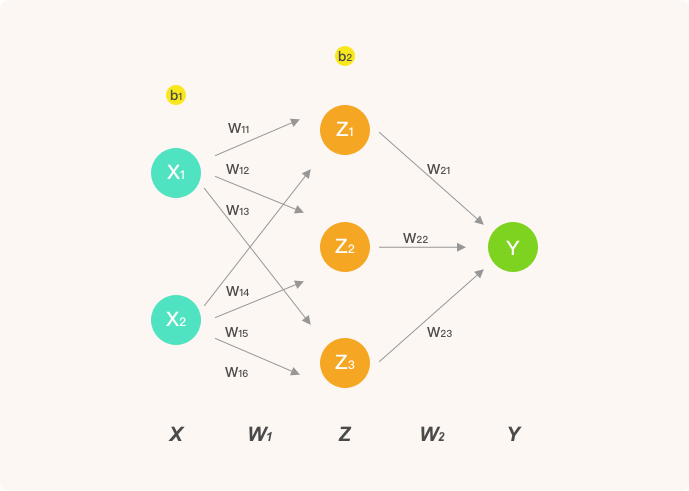
这篇文章中,我们使用的激活函数为 $sigmoid$ 函数:
由于下面要使用 $sigmoid$ 函数的导数,所以同样将其导数公式写出来:
然后,我们通过 Python 实现公式 $(17)$ :
def sigmoid(x):
# sigmoid 函数
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
# sigmoid 函数求导
return sigmoid(x) * (1 - sigmoid(x))
前向传播
前向(正向)传播中,每一个神经元的计算流程为:线性变换 → 激活函数 → 输出值。
同时,我们约定:
- $Z$ 表示隐含层输出,$Y$ 则为输出层最终输出。
- $w_{ij}$ 表示从第 $i$ 层的第 $j$ 个权重。
于是,上图中的前向传播的代数计算过程如下。
神经网络的输入 $X$,第一层权重 $W_1$,第二层权重 $W_2$。为了演示方便,$X$ 为单样本,因为是矩阵运算,我们很容易就能扩充为多样本输入。
接下来,计算隐含层神经元输出 $Z$(线性变换 → 激活函数)。同样,为了使计算过程足够清晰,我们这里将截距项表示为 0。
最后,计算输出层 $Y$(线性变换 → 激活函数):
下面实现前向传播计算过程,将上面的公式转化为代码如下:
# 示例样本
X = np.array([[1, 1]])
y = np.array([[1]])
X, y
然后,随机初始化隐含层权重。
W1 = np.random.rand(2, 3)
W2 = np.random.rand(3, 1)
W1, W2
前向传播的过程实现基于公式 $(21)$ 和公式 $(22)$ 完成。
input_layer = X # 输入层
hidden_layer = sigmoid(np.dot(input_layer, W1)) # 隐含层,公式 20
output_layer = sigmoid(np.dot(hidden_layer, W2)) # 输出层,公式 22
output_layer
反向传播
接下来,我们使用梯度下降法的方式来优化神经网络的参数。那么首先需要定义损失函数,然后计算损失函数关于神经网络中各层的权重的偏导数(梯度)。
此时,设神经网络的输出值为 $Y$,真实值为 $y$。然后,定义平方损失函数如下:
接下来,求解梯度 $\frac{\partial Loss(y, Y)}{\partial{W_2}}$,需要使用链式求导法则:
同理,梯度 $\frac{\partial Loss(y, Y)}{\partial{W_1}}$ 得:
其中,$\frac{\partial Y}{\partial{W_2}}$,$\frac{\partial Y}{\partial{W_1}}$ 分别通过公式 $(22)$ 和 $(21)$ 求得。接下来,我们基于公式对反向传播过程进行代码实现。
# 公式 24
d_W2 = np.dot(hidden_layer.T, (2 * (output_layer - y) *
sigmoid_derivative(np.dot(hidden_layer, W2))))
# 公式 25
d_W1 = np.dot(input_layer.T, (
np.dot(2 * (output_layer - y) * sigmoid_derivative(
np.dot(hidden_layer, W2)), W2.T) * sigmoid_derivative(np.dot(input_layer, W1))))
d_W2, d_W1
现在,就可以设置学习率,并对 $W_1$, $W_2$ 进行一次更新了。
# 梯度下降更新权重, 学习率为 0.05
W1 -= 0.05 * d_W1 # 如果上面是 y - output_layer,则改成 +=
W2 -= 0.05 * d_W2
W2, W1
以上,我们就实现了单个样本在神经网络中的 1 次前向 → 反向传递,并使用梯度下降完成 1 次权重更新。那么,下面我们完整实现该网络,并对多样本数据集进行学习。
# 示例神经网络完整实现
class NeuralNetwork:
# 初始化参数
def __init__(self, X, y, lr):
self.input_layer = X
self.W1 = np.random.rand(self.input_layer.shape[1], 3)
self.W2 = np.random.rand(3, 1)
self.y = y
self.lr = lr
self.output_layer = np.zeros(self.y.shape)
# 前向传播
def forward(self):
self.hidden_layer = sigmoid(np.dot(self.input_layer, self.W1))
self.output_layer = sigmoid(np.dot(self.hidden_layer, self.W2))
# 反向传播
def backward(self):
d_W2 = np.dot(self.hidden_layer.T, (2 * (self.output_layer - self.y) *
sigmoid_derivative(np.dot(self.hidden_layer, self.W2))))
d_W1 = np.dot(self.input_layer.T, (
np.dot(2 * (self.output_layer - self.y) * sigmoid_derivative(
np.dot(self.hidden_layer, self.W2)), self.W2.T) * sigmoid_derivative(
np.dot(self.input_layer, self.W1))))
# 参数更新
self.W1 -= self.lr * d_W1
self.W2 -= self.lr * d_W2
接下来,我们使用实验一开始的示例数据集测试,首先我们要对数据形状进行调整,以满足需要。
X = df[['X0', 'X1']].values # 输入值
y = df[['Y']].values # 真实 y
接下来,我们将其输入到网络中,并迭代 100 次:
nn = NeuralNetwork(X, y, lr=0.001) # 定义模型
loss_list = [] # 存放损失数值变化
for i in range(100):
nn.forward() # 前向传播
nn.backward() # 反向传播
loss = np.sum((y - nn.output_layer)**2) # 计算平方损失
loss_list.append(loss)
print("final loss:", loss)
plt.plot(loss_list) # 绘制 loss 曲线变化图
可以看到,损失函数逐渐减小并接近收敛,变化曲线比感知机计算会平滑很多。不过,由于我们去掉了截距项,且网络结构太过简单,导致收敛情况并不理想。这篇文章重点再于搞清楚 BP 的中间过程,准确度和学习难度不可两全。另外,需要注意的是由于权重是随机初始化,多次运行的结果会不同。
至此,我们已经完成了一个简单的人工神经网络的训练。实际上,这只是人工神经网络的冰山一角,而这种基础的简单神经网络结构往往用于真实问题的解决过程中。后面,我们将会学习更为复杂的神经网络结构,THE NEURAL NETWORK ZOO 这篇文章整理了大量不同类型的神经网络,相信你能从下图感受到人工神经网络的精彩世界。
补充视频
深度学习实际上就是人工神经网络的应用。国外知名科普视频作者 3Blue1Brown 制作了 4 个围绕人工神经网络讲解的视频,我们补充在下方供大家参考。由于视频版权归属者 3Blue1Brown 不允许转载,你需要通过以下链接跳转观看。
这四个视频制作的非常好。
小结
这篇文章从感知机的原理出发,带领大家用 Python 构建了一个单层神经网络结构,并完成了数据分类。紧接着,实验通过感知机引入了多层人工神经网络概念,并通过配图了解到了神经网络计算时广泛采用的反向传播算法。最后,通过 Python 构建了完整的 2 层神经网络结构。掌握这些内容后,已经达到了人工神经网络的学习要求。
相关链接
系列文章
- 感知机和人工神经网络
- TensorFlow 基础概念语法
- TensorFlow 构建神经网络
- TensorFlow 高阶 API 使用
- PyTorch 基础概念语法
- PyTorch 构建神经网络
- 卷积神经网络原理
- 卷积神经网络构建
- 图像分类原理与实践
- 生成对抗网络原理及构建
- 自动编码器原理及构建
- 目标检测原理与实践
- 循环神经网络原理
- 循环神经网络构建
- 文本分类原理与实践
- 自然语言处理框架拓展
- 神经机器翻译和对话系统
关联推荐
如果你觉得这篇文章对你有帮助,欢迎通过 微信赞赏码 或者 Buy Me a Coffee 请我喝杯 ☕️