图像分类原理与实践

介绍
这篇文章,我们将关注于机器学习工程应用上的图像分类问题。之前的实验中,我们实际上已经学会了使用简单的卷积神经网络来完成图像分类。实际上,对于一些较为复杂的数据集,简单的卷积神经网络无法达到一个较高的分类准确度,而深度学习实践中的网络结构通常可以达到几十甚至上百层的数目。所以在这次实验,我们将会使用已经被反复证明性能非常强悍的经典网络结构,并使用迁移学习来完成较为复杂的猫狗识别分类任务。
知识点
- 数据加载器
- 迁移学习
- 猫狗识别
- 卷积神经网络可视化
计算机视觉是一门研究如何使机器「看」的科学,其囊括了多种关键技术和应用场景。深度学习发展突飞猛进的今天,计算机视觉也迎来了新的发展趋势。目前,深度学习在计算机视觉方面主要擅长做:图像分类、对象检测、目标跟踪、语义分割、实例分割。
图像分类 Image Classification,是深度学习应用于计算机视觉中最具有代表性的一类实践场景。图像分类从字面意思上就很好理解,其可以运用到图像检索等实际任务中。对象检测 Object Detection,即检测图像中的关键对象。对象检测任务中,我们一般会使用边界框将检测对象框起来,并标记出置信度目标跟踪 Object Tracking,是指在特定场景跟踪某一个或多个特定感兴趣对象的过程,是无人驾驶的关键技术之一。语义分割 Semantic Segmentation,可以看作是对象检测的延伸,不仅需要标记出对象的边界框,还需要精确识别出各部分的边界。
最后,实例分割 Instance Segmentation 又是语义分割的拓展,例如用特定的颜色来标记同一类别对象的不同实例。

接下来,我们就尝试了解图像分类应用,并学会使用迁移学习的方法构建一个表现优秀的图像分类器。
数据集
这篇文章中,我们将解决著名的「猫狗识别」图像分类问题。「猫狗识别」是 Kaggle 上一个热度较高的图像分类大赛。训练集一共有 25000 标记好的猫狗照片,猫狗各占一半。测试集 12500 张,没有标定是猫还是狗,是比赛需要提交的预测结果。

这篇文章中,我们仅下载标记好的训练集。并在接下来的实验中,将该数据集按 $4:1$ 划分为训练集和验证集。这里叫验证集也是为了与 Kaggle 提供的原测试集进行区分。
接下来,实验下载「猫狗识别」挑战中提供标记好的 训练数据 [543 MB]。
wget -nc 'http://labfile.oss.aliyuncs.com/courses/1081/dogs_cats.zip' # 下载数据
!unzip -o "dogs_cats.zip" # 解压数据
数据集中,图片以 type.num.jpg 格式命名,分别代表标签和样本序号。例如:cat.9586.jpg 或 dog.1328.jpg 等。
接下来,遍历文件目录加载数据集:
import os
data_path = []
data_name = []
for root, dirs, files in os.walk('train'):
# 变量指定目录文件列表
for image_file in files:
image_path = os.path.join(root, image_file)
data_path.append(image_path)
data_name.append(image_file.split('.')[0])
len(data_path), len(data_name)
这个过程中,首先我们读取每张照片的路径保存到列表 data_path 中,然后通过对文件名切分来获取对应的标签。
让我们随机抽十六张图片来看看猫狗数据集中样本具体的样子。这里我们用到了 torchvision 工具提供的转换和显示方法。
pip install -U scikit-image # 安装 scikit-image
import random
from torchvision.utils import make_grid
from torchvision import transforms
from skimage import io, transform
import matplotlib.pyplot as plt
%matplotlib inline
# 随机抽取 16 张图片路径
img_path_list = random.sample(data_path, 16)
# 使用 skimage 根据路径读取图片并对显示尺寸进行裁剪
img_list = [transform.resize(io.imread(img_path), (100, 100), mode='reflect')
for img_path in img_path_list]
# 使用 torchvision 将图片处理成张量
img_list = [transforms.ToTensor()(img) for img in img_list]
# 将图片合并成每行四张的大图
img_show = make_grid(img_list, nrow=4, normalize=True)
plt.figure(figsize=(6, 6))
plt.imshow(img_show.permute(1, 2, 0).numpy())
看完猫狗数据集的图片之后,我们大致了解数据集是个什么样子的。接下来需要对标签进行预处理,毕竟在训练的时候,不能直接接受字符串的数据,只能是数字化的标签。
区别于前面的操作,此时可以使用 sklearn.preprocessing.LabelEncoder ↗ 对标签进行标准化,将字符串标签转换成从 0 开始的数字类标签。另外,该方法还可以反转标签,即将数字处理成字符串。当然,你也可以自己写一个判断语句来将字符串标签数值化。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(['cat', 'dog'])
data_label = le.transform(data_name)
data_label
对比字符标签,你应该能发现这里猫和狗分别用 0 和 1 进行了替换。
数据加载器
上面,我们大致做了两项数据准备工作。第一,读取到了图片路径,但尚未将图片处理成能输入网络的张量。第二,将图片标签转换为可用的类型。所以,接下来,我们将会利用 PyTorch 提供的一些列方法来制作一个图片数据加载器。
在正式制作 PyTorch 数据加载器之前,我们需要先了解一个概念叫 数据扩增 Data Augmentation。简单来讲,深度学习的效果非常依赖于数据集的规模,我们当然期望规模足够庞大的数据。不过,很多时候因为各种条件限制,数据集可能不够大。那么,对于图片数据来讲,就可以采用随机裁剪、旋转、镜像、去色等操作,将一张图片变换成不同视角和角度的多张图片,起到数据扩增的效果。除此之外,通过前面学习的 GAN 来生成新的图片也是数据扩增的一种方式。
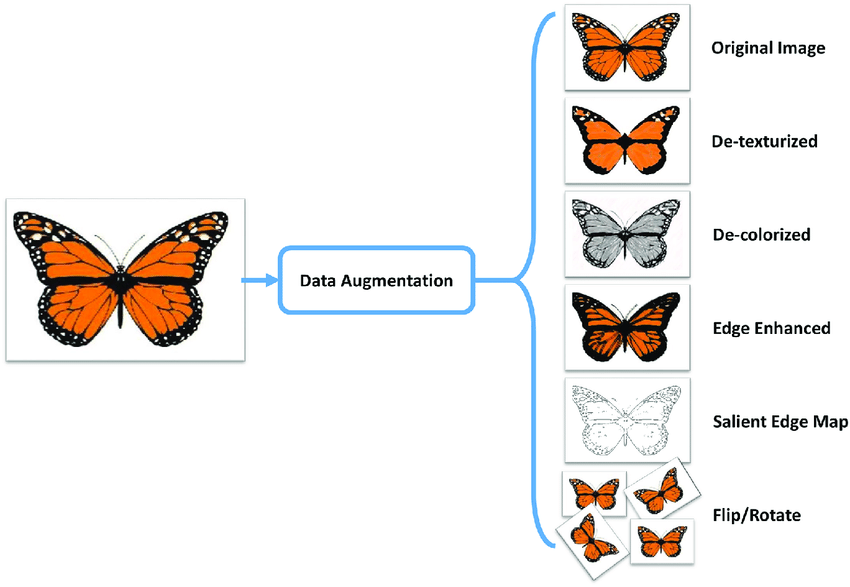
PyTorch 提供的 torchvision.transforms ↗ 内置了许多对图像处理函数,通过合理的组合就能起到数据扩增的效果。
来看一下这里将要用到的处理操作:
import numpy as np
# 加载图片并转换为 PIL IMAGE
IMAGE = transforms.ToPILImage()(io.imread(data_path[0]))
# 尺寸变形
scale = transforms.Resize(256)
# 随机裁剪
crop = transforms.RandomCrop(128)
# 打包方法
composed = transforms.Compose([transforms.Resize(256),
transforms.RandomCrop(224)])
# 将每个变换函数应用到一个样本上
fig = plt.figure()
for i, tsfrm in enumerate([scale, crop, composed]):
transformed_sample = np.array(tsfrm(IMAGE)) # PIL.image 转换成 np.ndarray
ax = plt.subplot(1, 3, i + 1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
ax.imshow(transformed_sample)
上面的示例中,ToTensor 将 PIL Image 或者 numpy.ndarray 转换成 PyTorch 中的 Tensor 类型。PIL Image和 numpy.ndarray 的数据格式为 height $\times$ width $\times$ channel,并且像素范围在 $[0, 255]$。转换后的 Tensor 则为 channel $\times$ height $\times$ width,范围在 $[0.0, 1.0]$ 之间。
最终返回的 3 张图依次为:仅使用 Resize 变换尺寸,仅使用 RandomCrop 随机裁剪,同时使用 Resize 和 RandomCrop 组合方法。
接下来,我们就来定义数据加载器需要的 transforms 预处理操作。
data_transforms = {
'train': transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(), # 水平镜像
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], # 用平均值和标准偏差归一化张量图像
[0.229, 0.224, 0.225]) # input = (input - mean) / std
]),
'val': transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(256),
transforms.CenterCrop(224), # 测试只需要从中间裁剪
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], # mean
[0.229, 0.224, 0.225]) # std
]),
}
其中,训练要做数据增强和数据标准化。而验证数据只需要裁剪成训练数据的尺寸而无需增强,因为这样才能保证评估的准确性。
定义好预处理操作之后,接下来,首先将数据按照 4:1 的比例分成训练集和验证集,直接使用大家熟悉的 train_test_split 函数。
from sklearn.model_selection import train_test_split
train_path, val_path, train_label, val_label = train_test_split(
data_path, data_label, test_size=0.2)
len(train_path), len(val_path), len(train_label), len(val_label)
还记得「生成动漫人物头像」实验中制作数据加载器时使用过的 torchvision.datasets.ImageFolder ↗ 吗?该方法可以直接读取自定义的图片文件夹,非常简便好用。但遗憾的是,这里无法使用该方法来加载猫狗识别图片。原因在于 torchvision.datasets.ImageFolder ↗ 的 API 要求图片存放的格式如下:
train/dog/xxx.jpg train/dog/xxy.jpg train/dog/xxz.jpg train/cat/123.jpg train/cat/nsdf3.jpg train/cat/asd932_.jpg
也就是说,你需要将不同类别的图片按照其类别分别用子文件夹存放。但我们提供的数据中,全部图片在一个文件夹中。
接下来,我们按照 PyTorch 官方教程提供的思路,通过继承并重写 torch.utils.data.Dataset ↗ 类来适应任意组织方式的图片数据。这一点希望对你之后的实际数据加载过程有所启发。
torch.utils.data.Dataset 是一个抽象类,自定义 Dataset 必须继承 torch.utils.data.Dataset,然后重写以下方法:
__len__: 返回数据集的大小。__getitem__: 通过索引读取并返回数据。
__init__ 中可以初始化变量或者只做一次的操作,例如读取 label 文件等。而在 __getitem__ 则用于读取图片,并返回图片数据和标签。
from torch.utils.data import Dataset
class DogcatDataset(Dataset):
def __init__(self, data_path, data_label, transform=None):
"""
- data_path (string): 图片路径
- data_label (string): 图片标签
- transform (callable, optional): 作用在每个样本上的预处理函数
"""
self.data_path = data_path
self.data_label = data_label
self.transform = transform
def __len__(self):
return len(self.data_path)
def __getitem__(self, idx):
img_path = self.data_path[idx]
image = io.imread(img_path)
label = self.data_label[idx]
# 如果有,则对数据预处理
if self.transform:
image = self.transform(image)
return image, label
接下来,分别初始化训练和测试的两个 Dataset:
# 初始化训练数据集
train_dataset = DogcatDataset(train_path, train_label,
data_transforms['train'])
# 初始化测试数据集
val_dataset = DogcatDataset(val_path, val_label,
data_transforms['val'])
train_dataset, val_dataset
Dataset 类可以使用 for i in range 循环迭代来加载。但实际开发,通常使用更高级的 torch.utils.data.DataLoader 进行迭代,因为其支持小批量加载,打乱数据,以及多线程读入特性。该方法在前面的实验中也已经学习过了。
import torch
# 训练数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=64, shuffle=True)
# 验证数据加载器
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=64, shuffle=False)
train_loader, val_loader
至此,我们重要完成了数据加载器的制作。你可能会发现这个过程会比想象中的复杂。实际上,由于前面的实验大多使用框架提供的内建数据集进行练习,所以其帮助我们省去了大量的中间过程。而在真实应用场景中,对数据的预处理和加载是较为麻烦的一项工作。
接下来使用数据加载器加载一个小批次验证其是否能正常工作。
for batch_index, sample_batch in enumerate(train_loader):
images, labels = sample_batch
sample_images = make_grid(images, normalize=True)
plt.figure(figsize=(8, 8))
plt.imshow(sample_images.permute(1, 2, 0).numpy())
break
有了数据加载器,是不是就可以搭建神经网络开始猫狗识别任务了呢?
当然可以。不过,对于没有学术背景的人来讲,自定义一个卷积神经网络结构可以完成像 MNIST 那种简单的图片分类,但对于猫狗识别这类问题而言是非常困难的。因为你缺乏经验。
所以,一般情况下。工程师应该尽可能沿用我们在卷积神经网络原理实验中提到过的比较经典的神经网络结构,而不是自行设计。比如:AlexNet,VGG,Google Net 和 ResNet 等。
这篇文章,我们先选择比较简单的 AlexNet 网络结构。不过,这里仍然不会自行使用 PyTorch 去搭建一个 AlexNet 从头开始训练。原因在于,虽然经过的数据扩增,但猫狗识别的数据集还是相对较小。于此同时,从头开始训练一个 AlexNet 所耗费的时间是非常长的。大概需要几个小时到十几个小时不等。
于是乎,这篇文章将带你了解一个新的学习方式:迁移学习。迁移学习不仅能让训练时间变短,且效果往往会比从头开始训练还要好很多。下面,我们就来学习这种两全其美的方法。
迁移学习概述
让我们通过一个直观的例子来说明什么是迁移学习。假设你穿越到了古代,成为了太子。为了治理好国家,你需要知道的实在太多了。若是从头学起,肯定是来不及。你要做的是找你的皇帝老爸,问问他正在做了什么,而他也希望能将他脑子的知识一次性的转移到你脑中。
这正是迁移学习,从以前的任务当中去学习知识或经验,并应用于新的任务当中。换句话说,迁移学习目的是从一个或多个源任务中抽取知识、经验,然后应用于一个目标领域当中去。比如说一个通用的语音模型迁移到某个人的语音识别,一个已训练好的图片分类模型迁移到医疗疾病识别上。
上面这段话听起来很简单,但要用神经网络的词语来表述,就是一层层网络中每个节点的权重从一个训练好的网络迁移到一个全新的网络里。而不是从头开始,为每特定的个任务训练一个神经网络。
这样做的好处可以从下面的例子中体现。假设已经有了一个可以高精确度分辨猫和狗的深度神经网络,之后想训练一个能够分别不同品种的狗的图片模型,你需要做的不是从头训练那些用来分辨直线,锐角的神经网络的前几层。而是利用训练好的网络,提取初级特征,之后只训练最后几层神经元,让其可以分辨狗的品种即可。
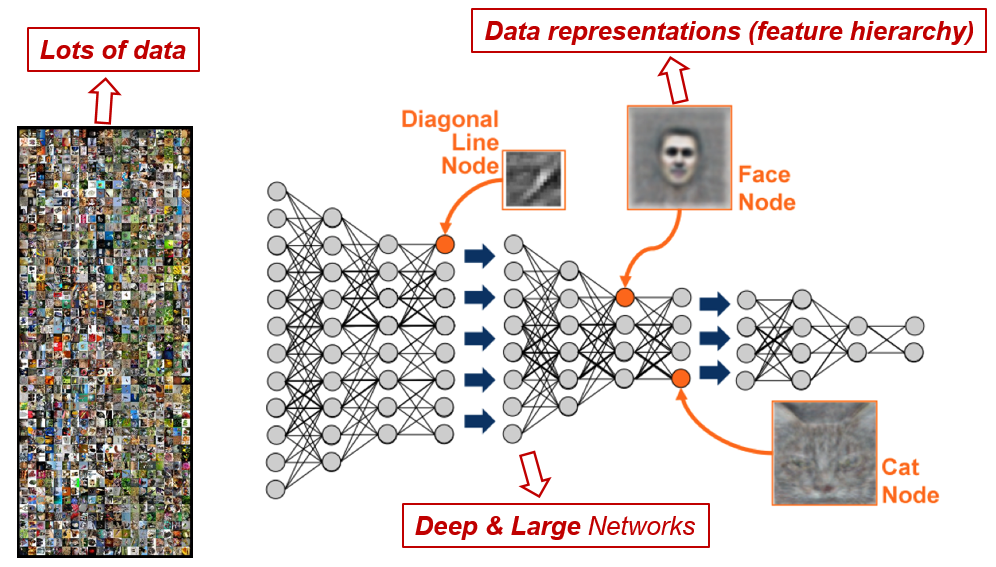
实际上,很少有人从头开始训练整个卷积网络(随机初始化),因为拥有足够大小的数据集是相对罕见的。相反,通常在非常大的数据集上预先训练 ConvNet,然后使用 ConvNet 作为感兴趣的任务的初始化或固定特征提取器。其中,ImageNet 就是一个常用的大规模数据集,其包含具有 2 万个类别的超过 1400 万个图像 ↗ 。前面提到的经典卷积神经网络,其论文大多都使用了在 ImageNet 上的评估结果。

迁移学习应用广泛,尤其是在工程界,无论是语音识别中应对不同地区的口音,还是通过电子游戏的模拟画面前期训练自动驾驶汽车。与此同时,迁移学习在学术界也是研究热点,其主要集中在以下几个方面:
- 通过半监督学习减少对标注数据的依赖,应对标注数据的不对称性。
- 通过迁移学习来提高模型的稳定性和可泛化性,不至于因为一个像素的变化而改变分类结果。
- 使用迁移学习来做到持续学习,让神经网络得以保留在旧任务中所学到的技能。
迁移学习策略
根据迁移学习的不同特点,一般情况下,迁移学习有以下 3 种不同的学习策略。这些策略的界限不是特别明显,相互之间又存在联系。
预训练模型
ImageNet 有几千万张图片,当前的卷积神经网络又相当复杂,有非常多的训练参数,因此即使在很多 GPU 上训练也要花 2~3 周,所以为了发布模型经常保存训练的模型参数,给需要的人用这个模型微调。很多深度学习框架都提供了预训练模型,例如最早的 Caffe 在 Model Zoo 开放了大量预训练的模型。这些模型可以直接拿来使用。
特征提取器
在 ImageNet 上预先训练一个卷积网络 ConvNet,删除最后一个全连接层(该层的输出是 ImageNet 的一个样本对应 1000 个类的概率),然后将其余的 ConvNet 视为新数据集的固定特征提取器。而重新为新的数据集训练线性分类器(例如线性 SVM 或 Softmax 分类器),例如在猫狗分类中有 2 类,分别是猫和狗,只需要训练最后一层用于实现二分类即可。
微调 Fine-tuning
这种策略是不仅在新数据集上替换和重新训练 ConvNet 之上的分类器,而且还通过继续反向传播来微调预训练网络的权重,可以微调 ConvNet 的所有层。当然由于过度拟合问题,也可以保留一些早期层,仅微调网络的某些更高级别部分。
普通预训练模型的特点是:用了大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。那么,当不做微调时,容易出现以下情况:
- 从头开始训练,需要大量的数据,计算时间和计算资源。
- 存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。
使用微调可以有效避免了上述可能存在的问题。一般情况下,当调参遇到下列情况时,就会考虑使用微调:
- 使用的数据集和预训练模型的数据集相似,如果不太相似,比如你用的预训练的参数是自然景物的图片,你却要做人脸的识别,效果可能就没有那么好了,因为人脸的特征和自然景物的特征提取是不同的,所以相应的参数训练后也是不同的。
- 自己搭建或者使用的卷积神经网络模型准确率太低,可以尝试微调是否提高自己的网络性能。
- 数据集相似,但数据集数量太少。
- 计算资源太少。
那么,我们该如何执行微调操作呢?可以从以下几点入手:
- 通常的做法是截断预先训练好的网络的最后一层(分类器),并用新的分类器替换它。例如,ImageNet 上预先训练好的网络带有 1000 个类别的 Softmax 层。如果新任务是对 10 个类别的分类,则网络的新 Softmax 层将由 10 个类别组成,而不是 1000 个类别。然后在网络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。
- 使用较小的学习率来训练网络。由于预先训练的权重相对于随机初始化的权重已经相当不错,所以一般不会过快地改变这些权重。所以,通常使用的初始学习率是从头训练(Training from scratch)的初始学习率的 1/10。
- 如果数据集数量过少,一般只训练最后一层。如果数据集数量中等,可以冻结预训练网络的前几层,训练后几层网络。因为前几个层捕捉了与新问题相关的通用特征,如曲线和边,我们希望保持这些权重不变。相反,一般会让网络专注于学习后续深层中特定于数据集的特征。
过拟合与欠拟合
在正式进行迁移学习之前,我们再详细了解一下过拟合和欠拟合的概念。机器学习中一个重要的话题便是模型的「泛化能力」,泛化能力强的模型才是好模型,对于训练好的模型,若在训练集表现差,不必说在测试集表现同样会很差,这可能是欠拟合导致;若模型在训练集表现非常好,却在测试集上差强人意,则这便是过拟合导致的。
在机器学习中,把模型在训练数据集上表现出的误差叫做训练误差,在任意一个测试数据样本上表现出的误差的期望值叫做泛化误差。
而欠拟合和过拟合在误差上的表现则分别是:
- 欠拟合:机器学习模型无法得到较低训练误差。
- 过拟合:机器学习模型的训练误差远小于其在测试数据集上的误差。
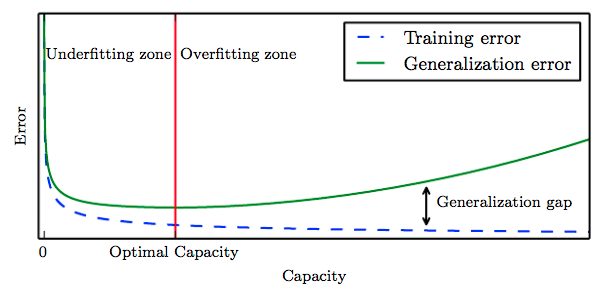
如上图所示,红线前半部分为欠拟合,泛化误差无法收敛(下降),红线后半部分则为过拟合,网络的训练误差在下降,但是泛化误差一直在升高而且高于训练误差。
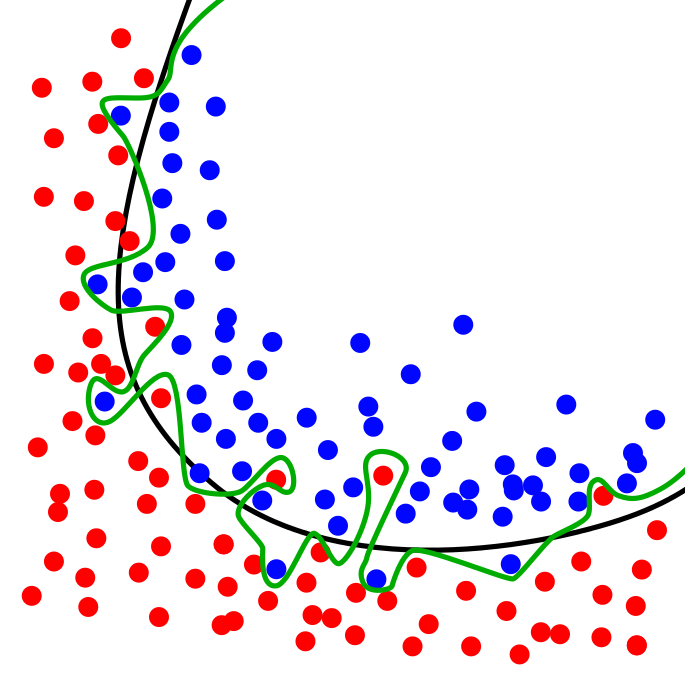
例如用一条曲线来分开平面上很多个点,红点和绿点对应训练集。绿线表示过拟合模型,黑线表示正则化模型。虽然绿线在训练数据的误差非常小,但是它太依赖于该数据,换句话说绿线过度地拟合了数据。所以与黑线相比,绿线可能在新添加的数据具有更高的误差,对应的就是测试集。
如果模型未考虑足够的信息,从而无法对现实世界精确建模,将产生欠拟合(Underfitting)现象。例如,如果仅观察下图指数曲线上的两点,可能会断言这里存在一个线性关系。但也有可能并不存在任何模式,因为只有两个点可供参考。在 $[-1,+1]$ 区间内,直线可对指数曲线取得良好的逼近效果:
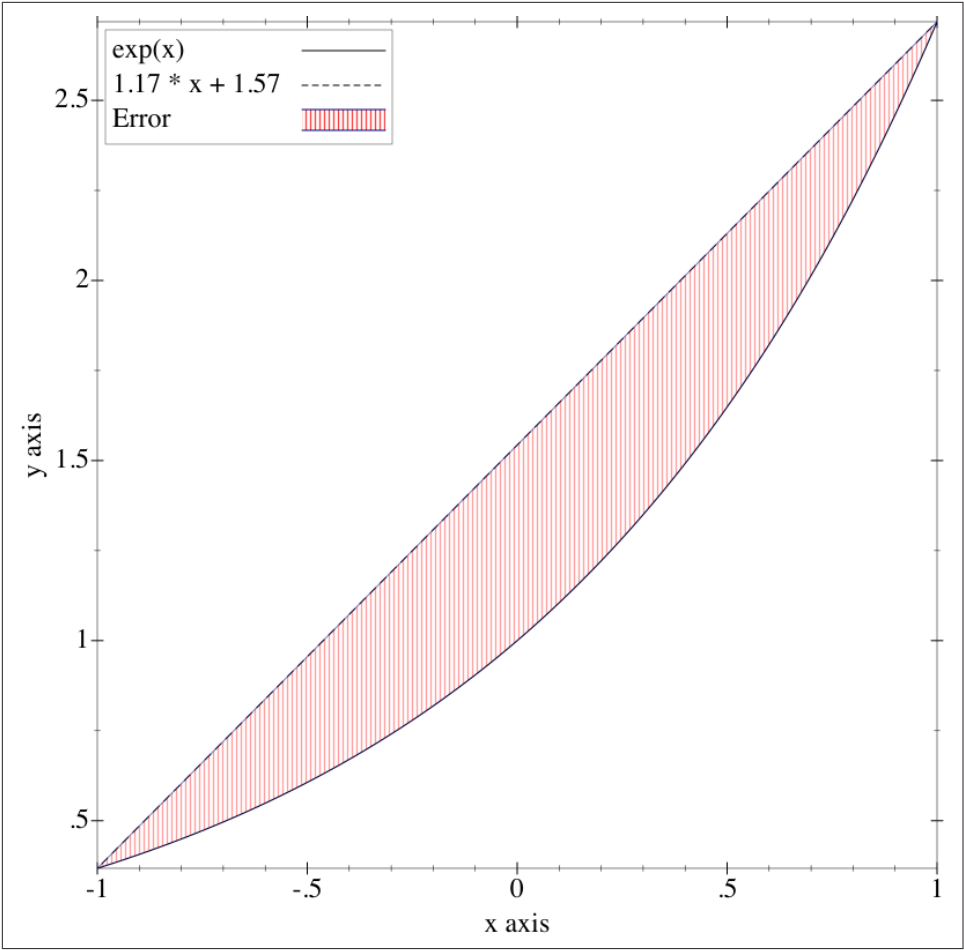
然而在 $[-20,20]$ 区间内,直线不仅无法拟合指数曲线,而且误差会非常大。由于此时的纵坐标取值非常大,所以虚线表示的函数图像已经接近与 X 轴。
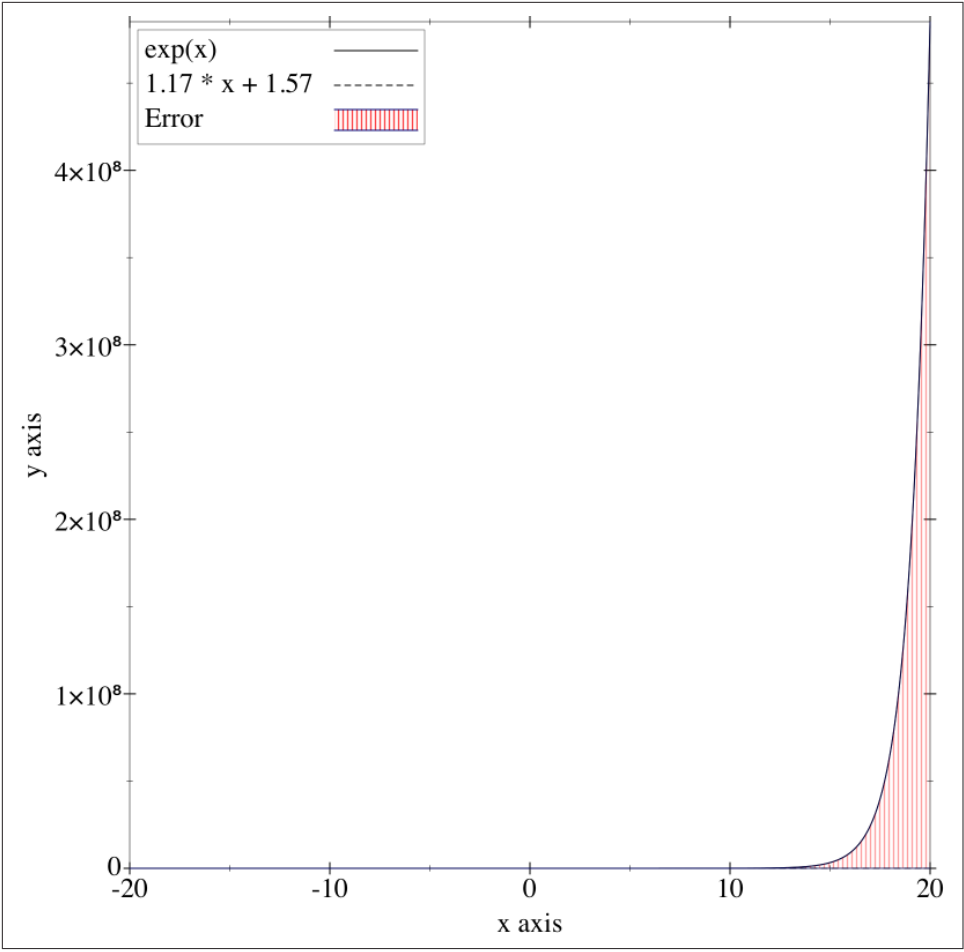
这就是过拟合,因为缺少样本,或者设置的特征数过少,导致模型无法获取足够的信息,从而无法得到一个良好的解。
一般情况下,当我们遇到过拟合时,主要有以下几种解决方法:
- 重新清洗数据。导致过拟合的一个可能原因是数据不纯,这就需要我们重新清洗数据。
- 训练数据量过少。此时可以增大训练数据占总数据的比例,或者进行数据扩增,例如反转、镜像、裁剪图片。
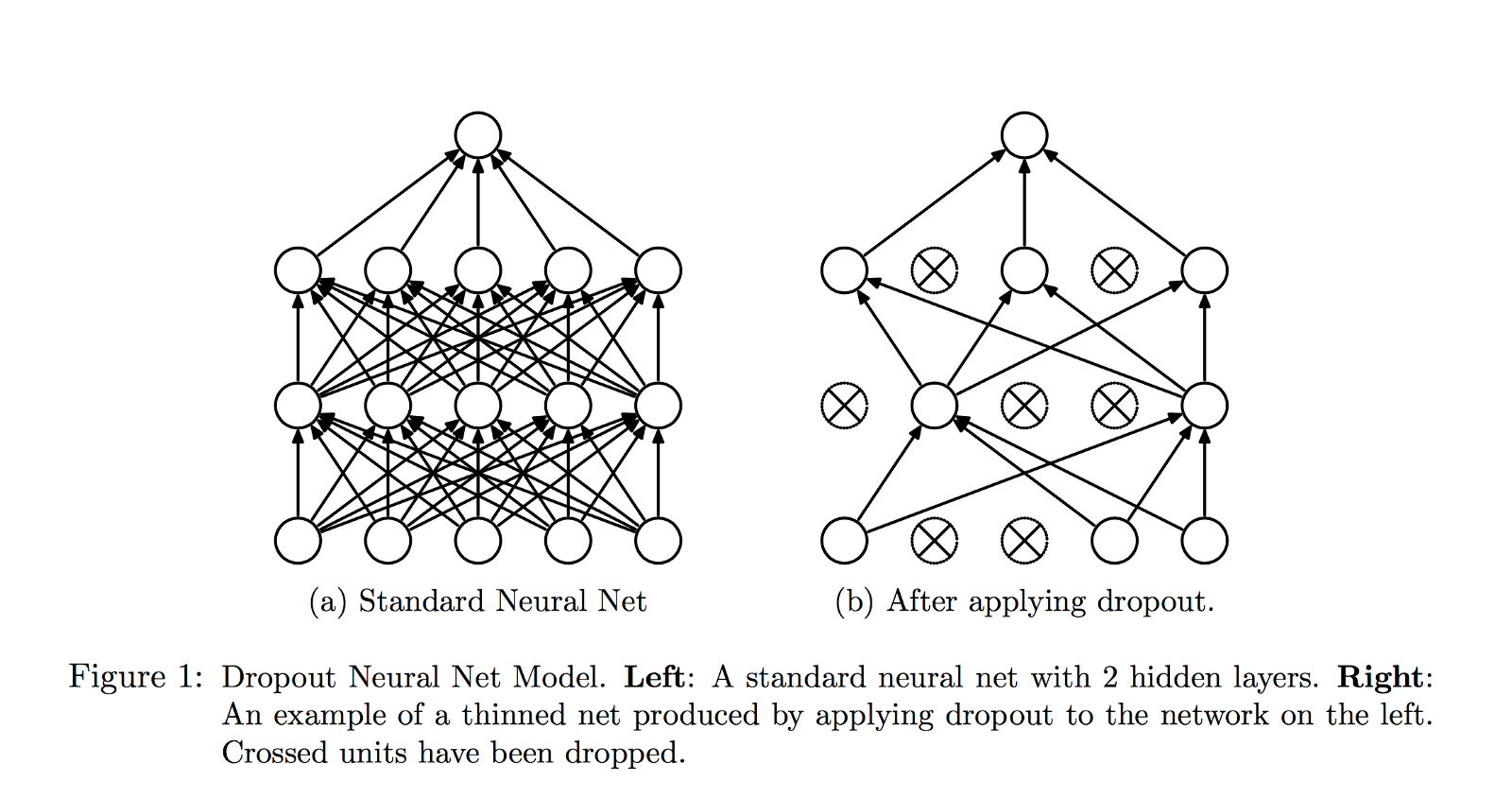
- 采用 Dropout 方法。Dropout 是一种神经网络的正则化方法,在训练的时候让神经元以一定的概率断开连接。
- Batch normalization 批量归一化。顾名思义,Batch normalization 就是对每批数据进行归一化处理,主要作用是加快网络的训练速度,但某种程度上也代替了 Dropout 的作用,Batch normalization 在训练阶段引入随机性,防止过度匹配。在测试阶段通过求期望等方式在全局去除掉这种随机性,从而获得确定而准确的结果。
- 添加 L1/L2 正则项。这种方法可以直接通过向训练参数添加惩罚项即可。
与之对应,欠拟合的解决方法会少很多。欠拟合主要是网络学习不到位导致的,那么可以通过改善网络结构完善。通常情况下,可以通过增加网络层数提高提取到的特征数,例如说把 AlexNet 换成 ResNet。
另外如果学习率选择不合适也可能表现出欠拟合、过拟合的特征。但事实上,这并不是由于欠拟合、过拟合导致的,具体形容为:
- Loss 抖动:学习率太大出现的超调现象,即在极值点两端不断发散,或是剧烈震荡,总之随着迭代次数增大 Loss 没有减小的趋势。
- Loss 下降速度很慢:学习率太小,导致卷积神经网络学习太慢的原因。
- Loss 爆炸,甚至超出了实数表达的范围:学习率超级大,优化器根本无法正常工作。
通常会选择一些学习率衰减策略,可以避免固定学习率遇到的以上问题:
- 步长衰减:每训练一定 Epoch 降低学习率,通常给定大小,例如是上一个学习率的 0.1。
- 指数衰减:按照公式 $\alpha = \alpha_0 e^{-k t}$ 衰减,其中 $\alpha_0, k$ 是超参数,$t$ 是迭代次数。
- 1/t 衰减:按照公式 $\alpha = \alpha_0 \div (1 + k t )$ 衰减,其中 $a_0, k$ 是超参数,$t$ 是迭代次数。
对于学习率衰减的方案,大多数深度学习框架都提供了相应的参数可供调整。
猫狗识别迁移学习
迁移学习中的微调相对简单,只需要加载与训练模型的权重,然后改变分类器输出的数目,重新训练即可。但是该方法花费的时间比较长。
因此,这里将介绍第二种将训练模型作为固定的特征提取器,只训练最后一层分类器。本次试验会使用到 AlexNet 预训练模型,我们之间从 PyTorch 中加载在 ImageNet 上完成预训练的 AlexNet 模型。↗
预训练模型[240MB] 下载需要时间,若进度异常缓慢,可强制中止重新执行下载。
from torchvision import models
# 从镜像镜像服务器上下载 AlexNet 预训练模型
torch.utils.model_zoo.load_url(
'http://labfile.oss.aliyuncs.com/courses/1233/alexnet-owt-4df8aa71.pth')
alexnet = models.alexnet(pretrained=True)
alexnet
如上所示,我们已经加载了 AlexNet 模型结构。接下来,需要完成 2 项工作。
因为采用了特征提取器的策略,首先需要固定最后一层分类器之外的所有层的权重。PyTorch 中所有层都会用一个变量 requires_grad 来表明这一层在反向传播时需不需要计算梯度。我们可以读取并打印每一层的梯度计算状态。
for param in alexnet.parameters():
print(param.requires_grad)
你可以看到,总共返回了 16 组状态。回到 AlexNet 网络,如果你仔细数的话一共包含 20 个网络层,那为什么这里只有 16 组呢?
实际上,AlexNet 网络中需要学习参数的层远没有 20 个层,其中只有卷积层和全连接层需要学习参数,池化层、Dropout、激活层等均没有可学习参数。所以,需要学习参数的卷积层和全连接层实际上只有 8 个。每一个层中权重和偏置项各为 1 组参数,所以最终打印出 $8 \times 2=16$ 组状态。
如果不需要计算梯度,当然也就不会更新权重。所以,只需要将该变量设置为 False 即可。
# 不需要更新权重
for param in alexnet.parameters():
param.requires_grad = False
print(param.requires_grad)
由于猫狗识别是 2 分类问题。而在 ImageNet 上完成预训练的 AlexNet 模型是 1000 个类别的多分类输出。所以,接下来需要替换掉最后一层分类器,并将输出类别改为 2。
classifier = list(alexnet.classifier.children()) # 读取分类器全部层
# 将最后一层由 Linear(4096, 1000) 改为 Linear(4096, 2)
classifier[-1] = torch.nn.Linear(4096, 2)
alexnet.classifier = torch.nn.Sequential(*classifier) # 修改原分类器
alexnet
此时,最后一层分类器的输出已变为 2。上面的代码中我们使用到了 Python 星号表达式,*classifier 表示把传入的参数放入名为 *args 的元组中。值得注意的是,新建层默认是 requires_grad=True,因为需要重新学习参数。所以,我们无需修改最后一个新的全连接层状态。
接下来做一下训练前的准备工作,定义损失函数和优化器。同时,这里需要指定学习率衰减策略,按步长更新来调整学习率,公式表达如下:
具体来讲,每迭代一个 step_size 次,学习率都将会是上一次的 gamma。
# 如果 GPU 可用则使用 CUDA 加速,否则使用 CPU 设备计算
dev = torch.device(
"cuda") if torch.cuda.is_available() else torch.device("cpu")
dev
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(filter(
lambda p: p.requires_grad, alexnet.parameters()), lr=0.001) # 优化器
# 学习率衰减,每迭代 1 次,衰减为初始学习率 0.5
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.5)
criterion, optimizer, lr_scheduler
上面的代码中,我们使用 filter() 过滤掉无需优化的参数,且使用 torch.optim.lr_scheduler.StepLR ↗ 来设定学习率衰减策略。
接下来,就可以开始训练了。这部分代码可以沿用前面 PyTorch 相似实验的训练代码框架。
epochs = 2
model = alexnet.to(dev)
print("Start Training...")
for epoch in range(epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(dev) # 添加 .to(dev)
labels = labels.to(dev) # 添加 .to(dev)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch [{}/{}], Batch [{}/{}], Train loss: {:.3f}'
.format(epoch+1, epochs, i+1, len(train_loader), loss.item()))
correct = 0
total = 0
for images, labels in val_loader:
images = images.to(dev) # 添加 .to(dev)
labels = labels.to(dev) # 添加 .to(dev)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
print('============ Test accuracy: {:.3f} ============='.format(
correct / total))
lr_scheduler.step() # 设置学习率衰减
两次迭代之后,准确度就已经超过了 95%,这是从头开始训练很难达到的。接下来,可以保存 PyTorch 模型以用于推理,直接使用 torch.save ↗ 将模型存在 .pt 文件即可。
torch.save(model.state_dict(), "model.pt")
"done."
然后,我们可以加载模型开始推理过程。
model_saved = alexnet
model_saved.load_state_dict(torch.load('model.pt'))
model_saved
你可以通过搜索引擎随便搜索一张图片用于测试。这里做一个有趣的实现,我们使用一个 猫猫狗狗随机发生器 接口来获取外部图片。
import requests
# 随机返回一只猫咪或狗狗的图片
random_api = "https://random-cat-dog.onrender.com"
content = requests.get(random_api).json()
with open("test.jpg", "wb") as f:
f.write(requests.get(content['url']).content)
plt.title(content['species'])
plt.imshow(io.imread("test.jpg"))
需要将外部图片经过同样的预处理过程,再输入到神经网络中。
IMAGE = io.imread("test.jpg")
IMAGE = data_transforms['val'](IMAGE).unsqueeze(0) # PyTorch 模型输入必须为 B*C*H*W
IMAGE.size()
torch.argmax(model_saved(IMAGE.to(dev)))# 对测试数据进行推理
如果最终返回 0 即代表为猫咪,1 则代表为狗狗。你可以用肉眼来观测准确度。
卷积神经网络可视化
卷积神经网络作为一个著名的深度学习领域的「黑盒」模型,已经在计算机视觉的诸多领域取得了极大的成功。但是,至今没有人能够打开这个黑盒,从数学原理上予以解释。这对理论研究者,尤其是数学家来说当然是不可接受的,但换一个角度来说,我们终于创造出了无法完全解释的事物,这也未尝不是一种进步。
当然,虽然无法完全打开这个黑盒,但是仍然出现了很多探索这个黑盒的尝试工作,其中一个工作就是卷积神经网络可视化。
当前学术界为探索卷积神经网络工作的理论基础做出了很多努力,例如 Learning Deep ... 这篇文章提出了一种确定卷积神经网络模型究竟在关注图片中的那一部分,或者说那一部分含有的信息最多,影响了卷积神经网络模型的判断,导致他输出当前类别。
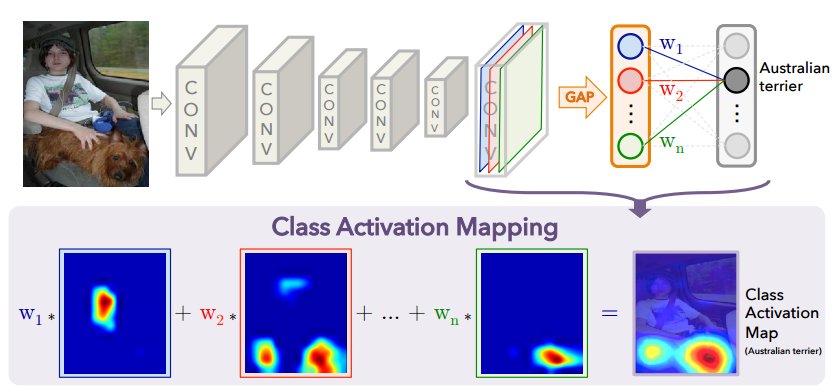
这个结果和人类一样,人类的大脑主要关注的图像的哪一部分。比如说我们看到一个人,如何判断她是个女人呢?当然是看脸、胸、衣服等等特征很明显的区域,根据这个原理,把它叫做深度学习中的「注意力机制」。类似的卷积神经网络可视化有很多种,比如:特征图(Feature map)可视化、权重可视化、Saliency map 等,这里我们将介绍权重可视化和特征图可视化。
最初的可视化工作见于 Imagenet classification ... ,也就是提出实验所使用到的 AlexNet 网络的论文。在这篇开创深度学习新纪元的论文中,Krizhevshy 直接可视化了第一个卷积层的卷积核。我们也可以复原这个过程。
conv1_weights = list(model_saved.parameters())[0]
conv1_images = make_grid(conv1_weights, normalize=True).cpu()
plt.figure(figsize=(8, 8))
plt.imshow(conv1_images.permute(1, 2, 0).numpy())
PyTorch 实现的 AlexNet 第一层卷积核参数的形状是 $64\times 3\times 11 \times 11$ 的四维 Tensor,这样就可以得到上述 $64$ 个$11\times 11$ 的图片块了。显然,这些重构出来的图像基本都是关于边缘,条纹以及颜色的信息。
我们知道,神经网络通过卷积核作为特征提取器,每一个卷积核对输入进行卷积,就产生一个特征图,例如说 AlexNet 第一层卷积层有 64 个卷积核,那么就有 64 个特征图。
理想的特征图应该是稀疏的以及包含典型的局部信息。通过特征图可视化能有一些直观的认识并帮助调试模型,比如:特征图与原图很接近,说明它没有学到什么特征,如果特征图几乎是一个纯色的图,说明它太过稀疏,可能是模型特征图数太多了,也反映了卷积核太小。我们可以通过这些信息调整神经网络的参数。
接下来可视化 AlexNet 的卷积层的特征图,并编写一个通用的可视化函数。
def visualize(alexnet, input_data, submodule_name, layer_index):
'''
alexnet: 模型
input_data: 输入数据
submodule_name: 可视化 module 的 name, 专门针对 nn.Sequential
layer_index: 在 submodule 中的 index
'''
x = input_data
modules = alexnet._modules
for name in modules.keys():
if (name == submodule_name):
module_layers = list(modules[name].children())
for i in range(layer_index+1):
if (type(module_layers[i]) == torch.nn.Linear):
x = x.reshape(x.size(0), -1) # 针对线性层
x = module_layers[i](x)
return x
x = modules[name](x)
然后,就可以尝试可视化第一个卷积层。
feature_maps = visualize(model_saved, IMAGE.to(dev), 'features', 0)
feature_images = make_grid(feature_maps.permute(1, 0, 2, 3), normalize=True).cpu()
plt.figure(figsize=(8, 8))
plt.imshow(feature_images.permute(1, 2, 0).numpy())
小结
这篇文章内容较多,了解并学习了迁移学习的相关知识,重点介绍了微调,过拟合、欠拟合的概念以及解决方法等内容。这些概念在实际开发、应用中基本都会利用到。实际训练时,我们很少重新开始训练,往往会利用已经训练好的预训练模型,所以要对这篇文章有充分地掌握。
相关链接
- Overfitting
- Classification: Instant Recognition with Caffe
- How to extract features of an image from a trained model
- Convolutional Neural Networks for Visual Recognition
系列文章
- 感知机和人工神经网络
- TensorFlow 基础概念语法
- TensorFlow 构建神经网络
- TensorFlow 高阶 API 使用
- PyTorch 基础概念语法
- PyTorch 构建神经网络
- 卷积神经网络原理
- 卷积神经网络构建
- 图像分类原理与实践
- 生成对抗网络原理及构建
- 自动编码器原理及构建
- 目标检测原理与实践
- 循环神经网络原理
- 循环神经网络构建
- 文本分类原理与实践
- 自然语言处理框架拓展
- 神经机器翻译和对话系统
关联推荐
如果你觉得这篇文章对你有帮助,欢迎通过 微信赞赏码 或者 Buy Me a Coffee 请我喝杯 ☕️