目标检测原理与实践

介绍
除了图像分类、图像生成、图像去噪,目标检测也是计算机视觉领域非常常见的一类问题,其在人脸检测,行人检测,图像检索和视频监控等方面有广泛应用。实际上,目标检测,在很多时候也会使用到图像分类的概念。这篇文章中,我们将了解什么是目标检测,以及目标检测的方法及应用。
知识点
- 目标检测方法
- R-CNN 家族
- YOLO 和 SSD
- Mask R-CNN
- TensorFlow Object Detection
目标检测,英文为 Object Detection,有时候也称之为物体检测,物体识别等。简单来讲,目标检测是与计算机视觉和图像处理有关的计算机技术,其涉及在数字图像和视频中检测特定类(例如人,建筑物或汽车)的语义对象的实例。目标检测在人脸检测,行人检测,图像检索和视频监控等计算机视觉领域有广泛的应用。动态物体检测与识别也是自动驾驶中需要攻克的一项关键技术。

在正式学习目标检测方法之前,我们首先需要尝试了解目标检测是什么。下面,假设我们建立一个自动驾驶汽车的路况检测系统。此时,自动驾驶汽车捕获了如下图所示的画面,你会如何描述这张图片?

画面上有其他正在行驶的汽车,准备过马路的行人以及交通信号灯。由于交通标志不清晰可见,汽车的路况检测系统应准确识别人们行走的位置,其他车辆的位置,交通信号灯的颜色,以便我们可以规划正确的路径。
那么路况检测系统可以做些什么呢?一般情况下,它可以做的是围绕物体创建一个边界框,以便系统可以确定人,汽车及其他物体在图像中的位置,然后相应地决定采取哪条路径,以避免任何意外。

所以,目标检测实际上就主要做一件事情。识别图像中指定存在的所有对象及其位置,并标示出来。
目标检测方法
接下来,我们开始了解常用与目标检测的方法。这里首先从最基础的开始。这里可以采取的最简单方法是将图像分为四个部分:

接下来,就是将分割之后的每一部分都提供给图像分类器,图像分类器会告诉我们该图像是否包含行人。如果有的话,即可使用边界框把该部分标记出来。

通过直观感受,你都知道这样做是不准确的。如果自动驾驶采用上面的方法,基本就是马路杀手了。当然,你可能会想到通过增加分割数量来改进,但仅仅这样做仍然是不够的。
发展到后来,就还是使用结构化的划分方法来提升目标检测的准确率。例如,我们可以将图像划分为 $10×10$ 网格。

此时,对于每一个网格,我们都可以以其为中心尝试取出包含不同数量临近网格的切片,最终提交给分类器。

然后由分类器给出准确率高且面积最小的切片,框定出目标物体。

看起来效果还不错,那么又没有可能继续改进呢?当然可以。如果此时增加网格大小且取出具有不同高度和纵横比的更多切片,标定红框一定会更加精准。不过可以想象,上面的这种方法时间复杂度太高。
随着深度学习的快速发展,目标检测的手段和方法也在快速迭代。目前,已经有大量使用深度学习进行特征选择并构建端到端的方法,这些方法使用深度神经网络来做出更严格和更精细的边界框预测。接下来,我们通过不涉及数学运算的图文介绍,带大家快速了解深度学习相关的目标检测方法。
R-CNN 家族
2013 年,Ross Girshick(简称 RBG)的 R-CNN 论文 Rich feature ... 横空出世,这也是利用卷积神经网络来做目标检测的开山之作。
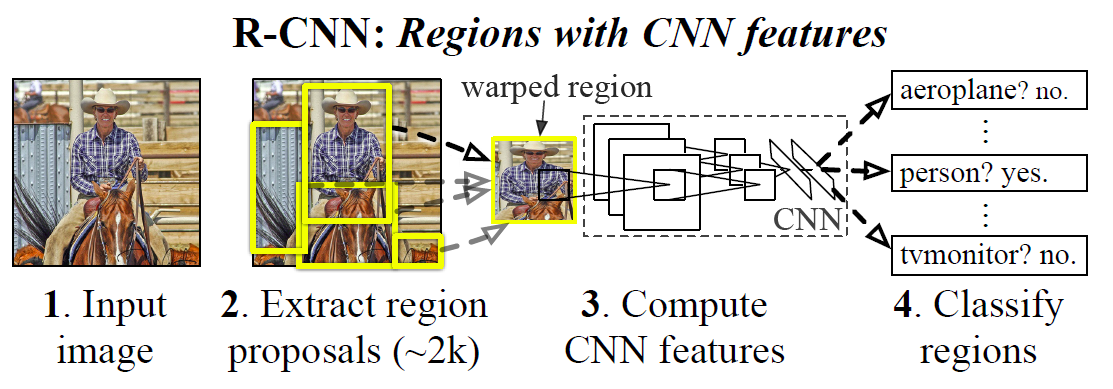
R-CNN 是 Regions with CNN features 的简称,意思是基于区域的卷积神经网络。其主要思路大致包含 3 个步骤:
- 利用启发式算法 Selective search 论文 生成约 2000 个 Region proposal 待检测区域。
- 将每个 Region proposal 输入卷积神经网络提取特征,再使用支持向量机完成分类。
- 训练一个线性回归模型收缩边界框。
下面,我们详细介绍这 3 个步骤。
传统的区域选择采用滑动窗口的思路,滑动窗口即指定窗口后以等间距在图像上依次移动,这样每滑一个窗口检测一次,相邻窗口信息重叠高,检测速度慢。

然而,R-CNN 使用了 Selective search 选择性搜索算法,先一次性生成候选区域后再检测。Selective search 虽然对于每张图片都生成了约 2000 个 Region proposal,但相比于穷举滑动窗口搜索的数量已经大大降低。关于 Selective search 方法,你可以阅读论文 What makes ...,其中也对比了除 Selective search 之外的其他相关候边界框搜索算法。
接下来,将每个 Region proposal 输入卷积神经网络提取特征,再使用支持向量机完成分类。而在这个过程中,支持向量机完成的是二分类问题,即判断是否属于该类别 yes 或者 no。
对于一个边界框而言,我们一般会使用 $(x,y,w,h)$ 坐标来表征其位置。 $(x, y)$ 是中心点坐标,$w$ 代表图片宽度,$h$ 表示图片高度。

既然坐标是数值,实际上就可以看作是回归问题,进而修正边界框的位置。R-CNN 引用了论文 Object Detection ... 提出的相关方法。
R-CNN 虽然相对于传统方法在检测准确度上高了很多,但仍然有 2000 多个候选区域,这就导致检测速度太慢。于是,后续有研究人员提出不同的改进方法,发展顺序为:R-CNN → SPP Net → Fast R-CNN → Faster R-CNN → Mask R-CNN。
SPP Net 论文 由何恺明团队提出,主要改进了候选区域生成和卷积顺序,且打破了固定尺寸输入的束缚。后续,RBG 又改进了 R-CNN,提出了 Fast R-CNN 论文 。其引用了 SPP Net 的工作,并主要优化了工作流程,提升效率。
再后来,何恺明团队又和 RBG 联手提出了 Faster R-CNN 论文,意思就是还可以变得更快。该方法的主要改进点在于利用神经网络生成候选区域,而非之前的选择性搜索,从而进一步提升了边界框的精度。2017 年,二人再联手发布了 Mask R-CNN 论文,该方法不仅可以做「目标检测」,还可以同时做「语义分割」,从而又一次更新了 R-CNN 家族。
YOLO 和 SSD
我们总结 R-CNN 家族的思路,实际上大致分为两步,即先生成 Region Proposal 或者先使用 CNN 提取特征,然后再使用分类器分类并修正边界框位置。
2015 年,YOLO 方法被提出 论文,区别于 R-CNN 家族两步走的战略,YOLO 直接采用回归方法一步确定边界框。它是怎么做到的呢?
YOLO 的全称是 You Only Look Once,即「你只需要看一次」。其方案简单粗暴,看起来和实验开始构建的路况检测系统相似。这里,我们直接引用论文中的图片进行解释。
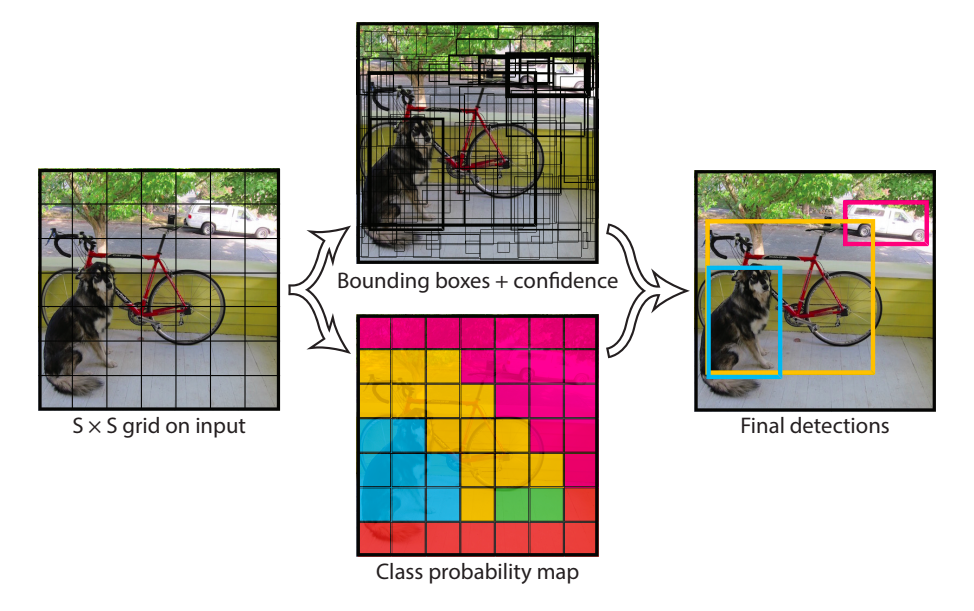
如上图所示,示例输入图片被划分为 $7*7$ 的网格。接下来,检测每个网格并输出边界框的 $(x,y,w,h)$ 和置信度。其中,置信度包含该网格内物体的类别及预测准确度。最后,将每个网格处理完使用 非极大值抑制 NMS 算法 去除重叠框并得到结果。
YOLO 改善了检测速度,但是对小物体的效果并不好。于是 SSD 论文 就在 YOLO 上添加了 Faster R-CNN 中 Anchor 的概念,并融合不同卷积层的特征做出预测。
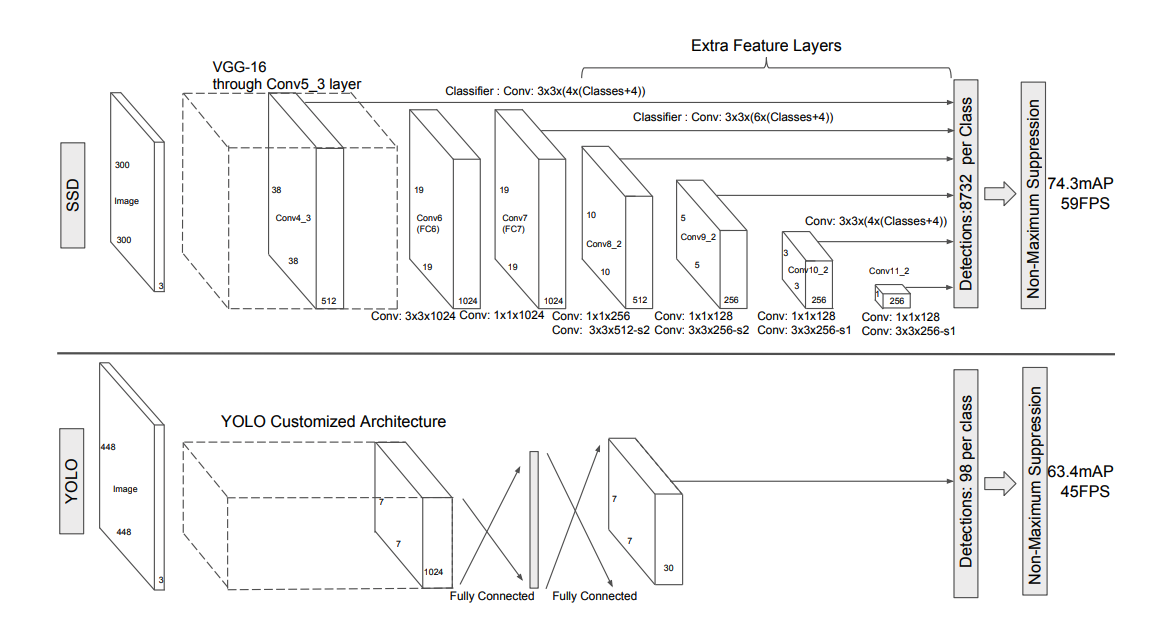
你可以通过上面的网络结构看出区别,SSD 结合了不同尺寸大小 Feature Maps 所提取的特征,然后进行预测,提升了对小物体的检测准确度。除此之外,SSD 省去了全连接层,减少了参数,提升了速度。
目标检测应用
上面,我们介绍了目标检测领域主要的两大类型方法。实际上,你可以把其归纳为一步或两步实现。YOLO 和 SSD 是典型的一步到位,直接利用分类器优秀的性能来回归出边界框位置。R-CNN 家族则是两步实现,一般需要先得到 Region proposal,再使用分类并修正边界框。当然,这两类方法也有各自的优势。YOLO 和 SSD 的主要优点在于「快」,而 R-CNN 家族则更「准」。
如果你想了解目标检测最近几年在学术领域的发展路线,可以关注 A paper list ... 项目,其归纳总结了比较完整的方法提出路线图。

接下来,我们尝试如何真正的将目标检测应用起来。
Mask R-CNN
Mask R-CNN 是 R-CNN 家族目前最为优秀的方法之一。Mask R-CNN 不仅可以完成「目标检测」,还可以同时用于计算机视觉中的「语义分割」。接下来,我们就尝试使用 Mask R-CNN 来完成图像目标检测任务。
关于 Mask R-CNN 模型实现,这篇文章不再学习,其原因在于涉及太多的延伸专业知识和模型较为复杂。有兴趣的学员请阅读 原论文,并参考 模型实现代码。
接下来,我们下载已经实现好的 Mask R-CNN 模型相关代码,并安装这篇文章所需要的依赖库。
目前,Mask R-CNN 官方仅提供 TensorFlow 1.x 支持,相应代码无法在 TensorFlow 2 上执行。
# 安装过程可能需持续数分钟,请耐心等待执行完成
git clone "https://github.com/lanqiao-courses/Mask_RCNN.git" # 克隆所需代码
pip install -r "Mask_RCNN/requirements.txt" # 安装依赖库
从头开始训练 Mask R-CNN 的难度较大,因为需要手动标定自己的数据集。所以,实验仍旧采用预训练模型的思路来体验目标检测的过程。首先,这里介绍数据集 COCO。
你应该非常熟悉 ImageNet 数据集了,这是图像分类时常用的基准数据集。大多数相关的科研论文也会引用在该数据集上的测试结果,用于体现自己研究成功的创新点和改进程度。COCO 同样也是一个知名的基准数据集,其经常用于目标检测,语义分割等领域。该数据集由微软贡献,最先通过论文 Microsoft COCO ... 提出。
COCO 目前包含超过 33 万张图片,其中大部分都进行了人工标定,也就是人工进行了物体边界框定。虽然 COCO 数据集只包含 80 个物体类别,但每类图片数量较多,所以能够提升模型对于特定类别的检测能力。你可以通过 ↗ 官方提供的页面 来预览数据集。
接下来,需要导入自定义的 Mask R-CNN 相关库,通过 sys.path.append 指定路径来加载,库名称为 mrcnn。
import sys
import warnings
warnings.filterwarnings('ignore')
sys.path.append("Mask_RCNN") # 链接到自定义 mrcnn 库
sys.path.append("Mask_RCNN/samples/coco/") # 链接到自定义 COCO 模块
我们下载 Mask R-CNN 在 COCO 数据集上的 预训练模型 [258 MB]。
import os
from mrcnn import utils
# 从镜像服务器上下载 Mask R-CNN 在 COCO 数据集上的预训练模型
utils.download_trained_weights("mask_rcnn_coco.h5", mirror='shiyanlou')
然后,我们将使用在 COCO 数据集上训练好的模型 mask_rcnn_coco.h5,该模型的配置位于 coco.py 的 CocoConfig 类中。由于实验的目标是模型推理(目标检测),所以需要继承 CocoConfig 类修改配置属性来适应推理过程。
import coco
class InferenceConfig(coco.CocoConfig):
# 设置 Batch size = 1 方便在单张图片上推理
# Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
config.display()
接下来,使用 mrcnn.model.MaskRCNN 初始化模型并置于推理模式,同时导入预训练模型权重。
import mrcnn.model as modellib
MODEL_DIR = os.path.abspath("logs") # 存放训练模型及日志路径
# 新建模型并置于推理模式
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# 加载预训练模型权重
model.load_weights("mask_rcnn_coco.h5", by_name=True)
model
正如上面介绍时所说,COCO 数据集实现了对 80 个常用物体类别的标定。对于这些类别的标签,你可以通过以下代码导入。
import coco dataset = coco.CocoDataset() # 下载 COCO 数据集 dataset.load_coco(COCO_DIR, "train") dataset.prepare() print(dataset.class_names) # 打印类别
由于 COCO 数据集体积太大,约 18 GB,这里就不直接下载了。实验将按 COCO 对标签的编码顺序来手动定义物体类别的标签。
# COCO 类别名称,顺序相关
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
class_names 中第一个为背景,后续为 80 个物体类别标签。由于关系到训练时的标定顺序,所以该标签顺序不能修改,否则最终的标定的类别会被搞混。
最后,我们选择实验一开始的示例图片进行目标检测。
import requests
from skimage import io
from matplotlib import pyplot as plt
%matplotlib inline
# 下载图片并保存为 test.jpg
url = "https://cdn.huhuhang.com/images/2023/05/document-uid214893labid7506timestamp1551679627073.jpg"
with open("test.jpg", "wb") as f:
f.write(requests.get(url).content)
plt.imshow(io.imread("test.jpg"))
model.detect 可用于目标检测,最终返回边界框等坐标信息。然后,通过 mrcnn.visualize 将标定可视化出来。
from mrcnn import visualize
image = io.imread("test.jpg")
results = model.detect([image], verbose=1) # 运行检测
r = results[0] # 可视化结果
visualize.display_instances(image, r['rois'], r['masks'],
r['class_ids'], class_names, r['scores'])
可以看的,大部分标定都是没有问题的,边界框也比较准确。不过图像底部中间所示的自动驾驶车辆的雷达被标记成了 person,应该是比较明显的错误。
至此,我们已经完成了使用 Mask R-CNN 在 COCO 上的预训练模型进行推理的过程。整个过程是比较简单的,对于 COCO 数据集涵盖的 80 种类别的物体,模型完全不用修改就可以使用。但如果你想对自己提供的数据集中特定的物体进行标定,那就需要手动制作数据集并重新开始 Mask R-CNN 的训练。这里有一篇文章 Instance Segmentation ... 可供阅读参考。
TensorFlow Object Detection
实际上,TensorFlow 同样提供了一套目标检测的工具叫 TensorFlow Object Detection API,该项目目前属于 TensorFlow Research 研究计划。TensorFlow Object Detection API 提供了十余组预训练模型,你可以通过 官方文档 页面详细了解。每一组模型都提供了所选择的使用方法及训练数据集,同时标明了性能。
| Model name | Speed (ms) | COCO mAP | Outputs |
|---|---|---|---|
| ssd_mobilenet_v1_coco | 30 | 21 | Boxes |
| ssd_mobilenet_v1_0.75_depth_coco | 26 | 18 | Boxes |
| ssd_mobilenet_v1_quantized_coco | 29 | 18 | Boxes |
| ssd_mobilenet_v1_0.75_depth_quantized_coco | 29 | 16 | Boxes |
| …… | …… | …… | …… |
同样,接下来我们参考 官方提供的示例,来尝试使用 TensorFlow Object Detection API 完成模型推理。首先,需要克隆 TensorFlow Object Detection 相关源码,源码已根据这篇文章进行了适当优化。
git clone "https://github.com/huhuhang/object_detection.git" # 克隆所需代码
sys.path.append("object_detection") # 链接到自定义 mrcnn 库
除此之外,由于 Tensorflow 对象检测 API 使用 Protobufs 配置模型和训练参数。在使用框架之前,必须编译 Protobuf 库。
apt-get update
apt-get install --yes protobuf-compiler # 安装编译工具
protoc object_detection/protos/*.proto --python_out=.
首先,下载一个 TensorFlow 提供的预训练模型。这里选择 SSD 在 COCO 数据集上完成训练,并使用 Mobilenet 进行特征提取的模型。选择这个模型的原因是其体积相对较小,但效果并不是最佳。更多的预训练模型,可以通过 此页面 找到 TensorFlow 提供的下载链接。
import six.moves.urllib as urllib
import tarfile
# 定义下载路径
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
PATH_TO_FROZEN_GRAPH = MODEL_NAME + '/frozen_inference_graph.pb'
# 下载预训练模型并解压
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
print("下载并解压完成.")
模型已经被下载到 ssd_mobilenet_v1_coco_2017_11_17/frozen_inference_graph.pb 路径下方。接下来,我们需要将预训练模型加载到内存中。
import tensorflow as tf
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
此时,需要定义一个函数 run_inference_for_single_image 用于模型在单张图片上进行推理检测。此函数取自于源代码,较为复杂可以直接执行。
import numpy as np
from object_detection.utils import ops as utils_ops
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {
output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(
tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(
tensor_dict['detection_masks'], [0])
real_num_detection = tf.cast(
tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [
real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [
real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(
output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
最后,读取测试图片,执行目标检测并完成边界框可视化。
from utils import visualization_utils as vis_util
from utils import label_map_util
# 读取测试图片
image_np = io.imread("test.jpg")
# 图片数组处理成模型期望的形状 [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# COCO 数据集标签
PATH_TO_LABELS = os.path.join('object_detection/data', 'mscoco_label_map.pbtxt')
category_index = label_map_util.create_category_index_from_labelmap(
PATH_TO_LABELS, use_display_name=True)
# 目标检测
output_dict = run_inference_for_single_image(image_np, detection_graph)
# 可视化检测边界框
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=10)
plt.figure(figsize=(12, 8))
plt.imshow(image_np)
你可以看出,相比于之前实验 Mask R-CNN 预训练模型,SSD MobileNet 要逊色不少。红绿灯,行人等都没有成功检测。当然,毕竟后者的预训练模型仅为前者 1/10 大小,且通常部署于移动平台。
小结
这篇文章,我们了解了计算机视觉中目标检测技术的历史和发展,认识了多种基于深度学习技术的目标检测方法。其中,重点对 R-CNN 家族进行了学习,并使用 MASK R-CNN 提供的预训练模型完成了对常用物体类别的检测推理过程。后续,实验对 TensorFlow Object Detection 进行了介绍,并完成了一个简单的流程示例。如果你对目标检测领域敢兴趣,还需要继续了解学习如何在自定义数据集上进行训练。
相关链接
- 基于深度学习的「目标检测」算法综述
- A paper list of object detection using deep learning
- Object detection with neural networks — a simple tutorial using keras
- Understanding and Building an Object Detection Model from Scratch in Python
- Is Google Tensorflow Object Detection API the easiest way to implement image recognition?
系列文章
- 感知机和人工神经网络
- TensorFlow 基础概念语法
- TensorFlow 构建神经网络
- TensorFlow 高阶 API 使用
- PyTorch 基础概念语法
- PyTorch 构建神经网络
- 卷积神经网络原理
- 卷积神经网络构建
- 图像分类原理与实践
- 生成对抗网络原理及构建
- 自动编码器原理及构建
- 目标检测原理与实践
- 循环神经网络原理
- 循环神经网络构建
- 文本分类原理与实践
- 自然语言处理框架拓展
- 神经机器翻译和对话系统
关联推荐
如果你觉得这篇文章对你有帮助,欢迎通过 微信赞赏码 或者 Buy Me a Coffee 请我喝杯 ☕️