装袋和提升集成学习方法
介绍
前面的实验都是独立的讲解每一个分类器的分类过程,每一个分类器都有其独有的特点并非常适合某些数据。但在实际中,由于数据的不确定性,单独应用个别分类器可能会出现分类准确率低的问题。为了应对这样的情况,集成学习被提出,其可以利用多个弱分类器结合的方式提高分类准确率。
知识点
- 集成学习概念
- 装袋算法 Bagging
- 随机森林 Random Forest
- 提升算法 Boosting
- 梯度提升树 GBDT
集成学习概念
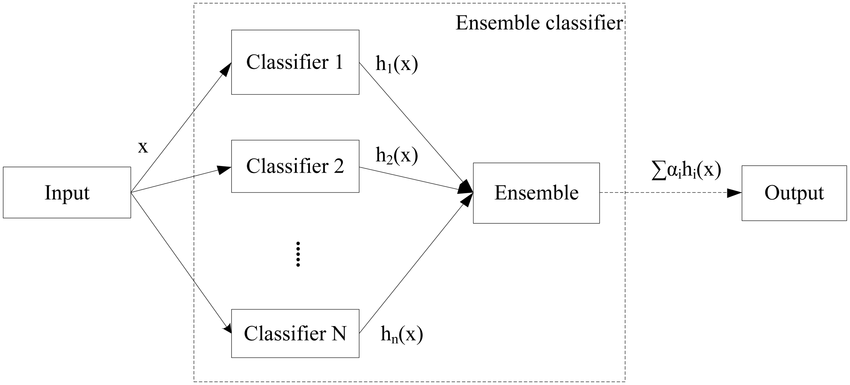
在学习装袋和提升算法之前,先引入一个概念:集成学习。集成学习(英文:Ensemble learning),顾名思义就是通过构建多个分类器并综合使用来完成学习任务,同时也被称为多分类器系统。其最大的特点就是结合各个弱分类器的长处,从而达到「三个臭皮匠顶个诸葛亮」的效果。
每一个弱分类器被称作「个体学习器」,集成学习的基本结构就是生成一组个体学习器,再用某种策略将他们结合起来。
从个体学习器类别来看,集成学习通常分为两种类型:
- 「同质」集成,在一个集成学习中,「个体学习器」是同一类型,如 「决策树集成」 所有个体学习器都为决策树。
- 「异质」集成,在一个集成学习中,「个体学习器」为不同类型,如一个集成学习中可以包含决策树模型也可以包含支持向量机模型。
同样从集成方式来看,集成学习也可以分为两类:
- 并行式,当个体学习器之间不存在强依赖关系时,可同时生成并行化方法,其中代表算法为装袋(Bagging)算法。
- 串行式,当个体学习器之间存在强依赖关系时,必须串行生成序列化方法,其中代表算法为提升(Boosting)算法。
结合策略
集成学习中,当数据被多个个体学习器学习后,如何最终决定学习结果呢?这里,我们假定集成包含 $T$ 个「个体学习器」${ h_{1},h_{2},…,h_{T}}$,常用的有三种方法来判定。
平均法
在数值型输出中,最常用的结合策略为平均法(Averaging),在平均法中有两种方式:
- 简单平均法:取每一个「个体学习器」学习后的平均值。
- 加权平均法:其中 $w_{i}$ 是每一个「个体学习器」 $h_{i}$ 的权重,通常为 $w_{i} \geq 0$。
投票法
对于分类输出而言,平均法显然效果不太好,最常用的结合策略为投票法(Voting),在投票法中主要有三种方式:
- 多数投票法:即在「个体学习器」分类完成后,通过投票选出分类最多的标签作为此次分类的结果。
- 加权投票法:同加权平均法类似,$w_{i}$ 是每一个「个体学习器」 $h_{i}$ 的权重,通常为 $w_{i}\geq 0$。
学习法
以上两种方法(平均法和投票法)相对比较简单,但是可能学习误差较大,为了解决这种情况,还有一种方法为学习法,其代表方法是 stacking ,当使用 stacking 的结合策略时, 不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,即把训练集弱学习器的学习结果作为输入,重新训练一个学习器来得到最终结果。
在这种情况下,我们将弱学习器称为初级学习器,将用于结合的学习器称为次级学习器。对于测试集,首先用初级学习器预测一次,得到次级学习器的输入样本,再用次级学习器预测一次,得到最终的预测结果。
装袋算法 Bagging
在大致了解集成学习相关概念之后,接下来就是对集成学习中常用算法思想之一的装袋算法进行详细的讲解。
装袋算法是并行式集成学习的代表,其原理也比较简单。算法步骤如下:
- 数据处理:将数据根据实际情况进行清洗整理。
- 随机采样:从样本中随机选出 $m$ 个样本作为一个子样本集。有放回的重复 $T$ 次,得到 $T$ 个子样本集。
- 个体训练:设定 $T$ 个个体学习器,将每一个子样本集放入对应个体学习器进行训练。
- 分类决策:用投票法集成进行分类决策。
Bagging Tree
在前一节的决策树讲解中提到,决策树是一个十分「完美」的训练器,但特别容易出现过拟合的情况,最终导致预测准确率低的问题。事实上在装袋算法中,决策树常常被用作弱分类器。下面我们通过具体实验来看看决策树和以决策树作为装袋算法的预测效果。
这篇文章使用在上一章讲决策树时所用的学生成绩预测数据集。其中数据处理已在上一章详细说明,这篇文章我们使用处理过后的数据集。数据集名称为 course-14-student.csv,加载并预览数据集:
import pandas as pd
data = pd.read_csv(
"https://labfile.oss.aliyuncs.com/courses/1081/course-14-student.csv", index_col=0)
data.head()
加载好预处理的数据集之后,为了应用装袋算法,需要将数据集分为训练集和测试集,依照经验:训练集占比为 70%,测试集占 30%。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data.iloc[:, :-1], data["G3"],
test_size=0.3, random_state=35)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
作为比较,首先将该数据集用决策树的方式进行预测,使用 scikit-learn 实现决策树预测的用法在前一章节已详细介绍,这篇文章直接使用。
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier(criterion='entropy', random_state=34)
dt_model.fit(X_train, y_train) # 使用训练集训练模型
dt_y_pred = dt_model.predict(X_test)
dt_y_pred
from sklearn.metrics import accuracy_score
accuracy_score(y_test, dt_y_pred) # 计算使用决策树预测的准确率
由于这篇文章所采用的数据集特征值比前一章节多,所以决策树泛化能力更差。
单棵决策树的预测结果并不能使我们满意,下面我们使用 装袋(Bagging) 的思想来提高预测准确率。我们通过 scikit-learn 来对 Bagging Tree 算法进行实现。
BaggingClassifier(base_estimator=None, n_estimators=10, max_samples=1.0, max_features=1.0)
其中:
base_estimator:表示基础分类器(弱分类器)种类,默认为决策树 。n_estimators:表示建立树的个数,默认值为 10 。max_samples:表示从抽取数据中选取训练样本的数量,Int(整型)表示数量,Float(浮点型)表示比例,默认为所有样本。max_features:表示抽取特征的数量,Int(整型)表示数量,Float(浮点型)表示比例,默认为所有特征。
from sklearn.ensemble import BaggingClassifier
tree = DecisionTreeClassifier(criterion='entropy', random_state=34) # 使用决策树作为基学习器
bt_model = BaggingClassifier(tree, n_estimators=100,
max_samples=1.0, random_state=3)
bt_model.fit(X_train, y_train)
bt_y_pred = bt_model.predict(X_test)
bt_y_pred
accuracy_score(y_test, bt_y_pred) # 计算使用决策树预测的准确率
根据准确率可以看到在决策树通过装袋(Bagging)算法后预测准确率有明显提升。
随机森林 Random Forest
其实,Bagging Tree 算法,是应用子数据集中的所有特征构建一棵完整的树,最终通过投票的方式进行预测。而随机森林就是在 Bagging Tree 算法的基础上进行进一步的改进。
随机森林的思想就是将一个大的数据集使用自助采样法进行处理,即从原样本数据集中随机抽取多个子样本集,并基于每一个子样本集生成相应的决策树。这样,就可以构建出由许多小决策树组形成的决策树「森林」。最后,实验通过投票法选择决策树最多的预测结果作为最终的输出。
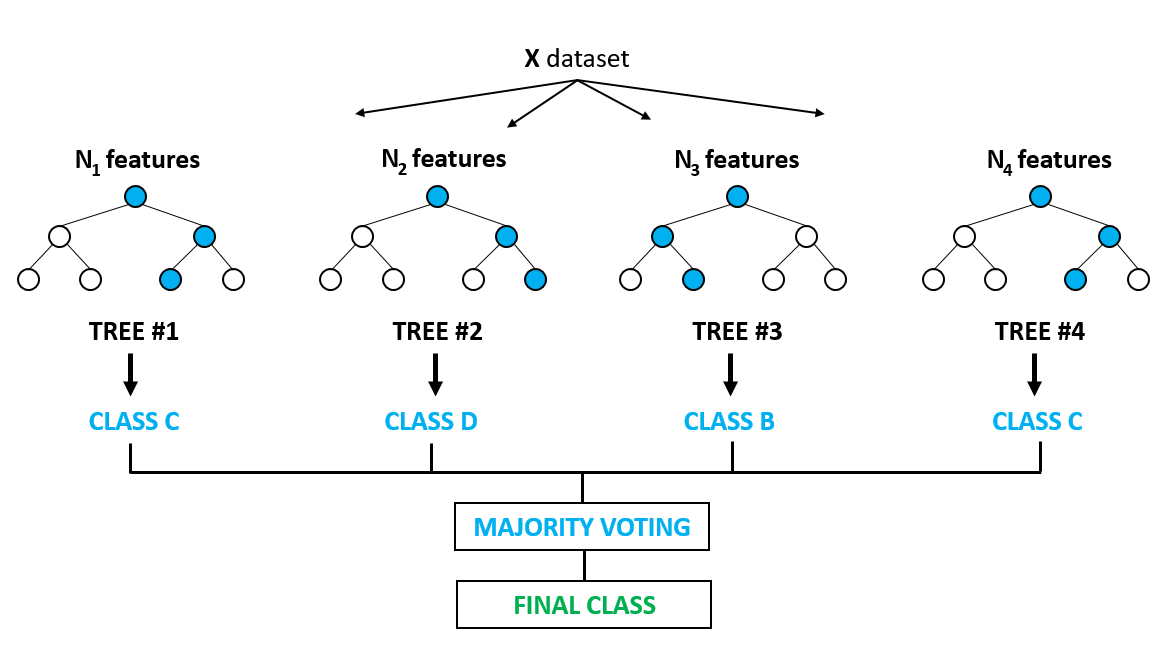
所以,随机森林的名称来源就是「随机抽样 + 决策树森林」。
随机森林算法原理
随机森林作为装袋(Bagging)的代表算法,算法原理和装袋十分相似,但在此基础上做了一些改进:
- 对于普通的决策树,会在 N 个样本的所有特征中选择一个最优划分特征,但是随机森林首先会从所有特征中随机选择部分特征,再从该部分特征中选择一个最优划分特征。这样进一步增强了模型的泛化能力。
- 在决定部分特征个数时,通过交叉验证的方式来获取一个合适的值。
随机森林算法流程:
- 从样本集中有放回随机采样选出 $n$ 个样本。
- 从所有特征中随机选择 $k$ 个特征,对选出的样本利用这些特征建立决策树。
- 重复以上两步 $m$ 次,即生成 $m$ 棵决策树,形成随机森林。
- 对于新数据,经过每棵树决策,最后投票确认分到哪一类。
模型构建和数据预测
在划分好数据集之后,接下来就是进行模型的构建以及预测。下面我们通过 scikit-learn 来对其进行实现。
RandomForestClassifier(n_estimators, criterion, max_features, random_state=None)
其中:
n_estimators:表示建立树的个数,默认值为 10 。criterion:表示特征划分方法选择,默认为gini,可选择为entropy(信息增益)。max_features:表示随机选择特征个数,默认为特征数的根号。
from sklearn.ensemble import RandomForestClassifier
# 这里构建 100 棵决策树,采用信息熵来寻找最优划分特征。
rf_model = RandomForestClassifier(
n_estimators=100, max_features=None, criterion='entropy')
rf_model.fit(X_train, y_train) # 进行模型的训练
rf_y_pred = rf_model.predict(X_test)
rf_y_pred
当我们训练好模型并进行分类预测之后,可以通过比对预测结果和真实结果得到预测的准确率。
accuracy_score(y_test, rf_y_pred)
可以通过结果看到,这篇文章的数据集用随机森林预测的准确率和用 Bagging Tree 预测的准确率差别不大,但随着数据集的增大和特征数的增多,随机森林的优势就会慢慢显现出来。
提升算法 Boosting
当「个体学习器」之间存在较强的依赖时,采用装袋的算法便有些不合适,此时最好的方法就是使用串行集成方式:提升(Boosting)。
提升算法是可以将弱学习器提升为强学习器的算法,其具体思想是从初始训练集训练出一个「个体学习器」,再根据个体学习器的表现对训练样本分布进行调整,使得在个体学习器中判断错的训练样本在后续受到更多的关注,然后基于调整后的样本分布来训练下一个「个体学习器」。如此重复进行,直至个体学习器数目达到事先指定的值 T,最终将这 T 个「个体学习器」输出的值进行加权结合得到最终的输出值。
Adaboost
提升(Boosting)算法中最具代表性的算法为 Adaboost。
AdaBoost(Adaptive Boosting)名为自适应增强,其主要自适应增强表现在:上一个「个体学习器」中被错误分类的样本的权值会增大,正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数才确定最终的强分类器。
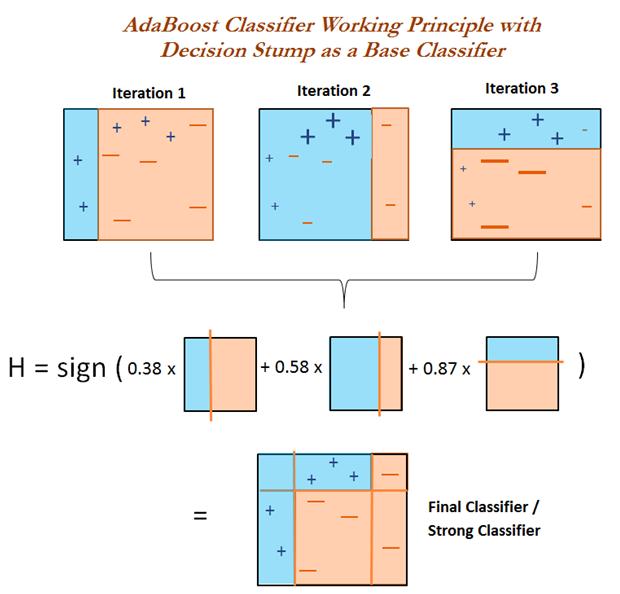
AdaBoost 算法与 Boosting 算法不同的是,其不需要预先知道弱分类器的误差,并且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度。
Adaboost 算法流程:
- 数据准备:通过数据清理和数据整理的方式得到符合规范的数据。
- 初始化权重:如果有 $N$ 个训练样本数据,在最开始时每一个数据被赋予相同的权值:$1/N$。
- 弱分类器预测:将有权重的训练样本放入弱分类器进行分类预测。
- 更改权重:如果某个样本点被准确地分类,降低其权值;若被分类错误,那么提高其权值。然后,权值更新过的样本集被用于训练下一个分类器。
- 强分类器组合:重复 3,4 步骤,直至训练结束,加大分类误差率小的弱分类器的权重(这里的权重和样本权重不一样),使其在最终的分类函数中起着较大的决定作用,降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用,最终输出结果。
模型构建和数据预测
在划分好数据集之后,接下来就是进行模型的构建以及预测。下面我们通过 scikit-learn 来对其进行实现。
AdaBoostClassifier(base_estimators,n_estimators)
其中:
base_estimators:表示弱分类器种类,默认为 CART 分类树。n_estimators:表示弱学习器的最大个数,默认值为50。
from sklearn.ensemble import AdaBoostClassifier
ad_model = AdaBoostClassifier(n_estimators=100)
ad_model.fit(X_train, y_train)
ad_y_pred = ad_model.predict(X_test)
ad_y_pred
accuracy_score(y_test, ad_y_pred) # 计算使用决策树预测的准确率
通过结果可以看到,应用 Adaboost 算法得到的准确率和决策树在该数据集上相差不大。
梯度提升树 GBDT
梯度提升树(Gradient Boosting Decison Tree,GBDT)同样是 Boosting 算法家族中的一员, Adaboost 是利用前一轮迭代弱学习器的误差率来更新训练集的权重,而梯度提升树所采用的是前向分布算法,且弱学习器限定了只能使用 CART 树模型。
在 GBDT 的迭代中,假设我们前一轮迭代得到的强学习器是 $f_{t-1}(x)$ ,损失函数是 $L(y,f_{t-1}(x))$ ,我们本轮迭代的目标是找到一个 CART 回归树模型的弱学习器 $h_{t}(x)$ ,让本轮的损失 $L(y,f_{t}(x) = L(y ,f_{t−1}(x)+h_{t}(x))$ 最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
算法流程:
- 数据准备:通过数据清理和数据整理的方式得到符合规范的数据。
- 初始化权重:如果有 $N$ 个训练样本数据,在最开始时每一个数据被赋予相同的权值:$1/N$。
- 弱分类器预测:将有权重的训练样本放入弱分类器进行分类预测。
- CART 树拟合:计算每一个子样本的梯度值,通过梯度值和子样本拟合一棵 CART 树
- 更新强学习器:在拟合好的 CART 树中通过损失函数计算出最佳的拟合值,更新先前组成的强学习器。
- 强分类器组合:重复 3,4,5 步骤,直至训练结束,得到一个强分类器,最终输出结果。
在划分好数据集之后,接下来就是进行模型的构建以及预测。下面我们通过 scikit-learn 来对其进行实现。
GradientBoostingClassifier(max_depth = 3, learning_rate = 0.1, n_estimators = 100, random_state = None)
其中:
max_depth:表示生成 CART 树的最大深度,默认为 3learning_rate:表示学习效率,默认为 0.1。n_estimators:表示弱学习器的最大个数,默认值为 100。random_state:表示随机数种子。
from sklearn.ensemble import GradientBoostingClassifier
gb_model = GradientBoostingClassifier(
n_estimators=100, learning_rate=1.0, random_state=33)
gb_model.fit(X_train, y_train)
gb_y_pred = gb_model.predict(X_test)
gb_y_pred
accuracy_score(y_test, gb_y_pred) # 计算使用决策树预测的准确率
可以看到,在使用装袋和提升算法时,在大部分情况下,会产生更好的预测结果,但有时也可能出现没有优化的情况。事实上,机器学习分类器的选择就是如此,没有最好的分类器只有最适合的分类器,不同的数据集,由于其数据特点的不同,在不同的分类器中表现也不同。
小结
这篇文章中学习了集成学习中装袋和提升算法的原理,且分别讲解了每个类别中具有代表性的算法 Bagging Tree 和随机森林以及 Adaboost 和梯度提升树,并用 scikit-learn 对算法进行实现。
相关链接
系列文章
- 综述及示例
- 线性回归实现与应用
- 多项式回归实现与应用
- 岭回归和 LASSO 回归实现
- 回归模型评价与检验
- 逻辑回归实现与应用
- K-近邻算法实现与应用
- 朴素贝叶斯实现及应用
- 分类模型评价方法
- 支持向量机实现与应用
- 决策树实现与应用
- 装袋和提升集成学习方法
- 划分聚类方法实现与应用
- 层次聚类方法实现与应用
- 主成分分析原理及应用
- 密度聚类方法实现与应用
- 谱聚类及其他聚类方法应用
- 自动化机器学习综述
- 自动化机器学习实践应用
- 模型动态增量训练
- 模型推理与部署
关联推荐
如果你觉得这篇文章对你有帮助,欢迎通过 微信赞赏码 或者 Buy Me a Coffee 请我喝杯 ☕️