自动化机器学习实践应用
介绍
auto-sklearn 是基于 scikit-learn 开发的自动化机器学习框架。它延续了 scikit-learn 的易用性,并进一步引入自动化机器学习的方法来方便非专业开发者建立预测模型。这篇文章,我们将学习 auto-sklearn 的使用,并讨论自动化机器学习的优势和劣势。
知识点
- auto-sklearn 框架介绍
- 自动化分类和回归算法
- 自动化机器学习的优劣
auto-sklearn 介绍
auto-sklearn 看名字你应该就能发现它和 scikit-learn 的相关性。的确,auto-sklearn 是基于 scikit-learn 开发的自动化机器学习库。不过,auto-sklearn 并不是由 scikit-learn 开发团队维护,而是由第三方机构 automl.org 开发维护。该机构人员来源于德国弗莱堡大学机器学习研究室。
auto-sklearn 框架采用了我们在综述部分提过的 Auto-WEKA 全局优化思想。为了改进泛化,auto-sklearn 在全局优化测试过程中基于所有模型构建集成学习过程。为了加速优化过程,auto-sklearn 使用了元学习来识别类似的数据集并运用已有的经验。auto-sklearn 总共包含 15 种分类算法,14 种特征预处理算法,并负责数据缩放,分类参数编码和缺失值处理。
在本地使用 auto-sklearn 时需要按照 官方说明 进行安装,不同的系统步骤稍有区别。
# 安装 auto-sklearn,该步骤不一定适用于本地安装
pip install auto-sklearn
auto-sklearn API 主要分为 4 个部分:
- Classification:分类问题相关的训练方法。
- Regression:回归问题相关的训练方法。
- Metrics:算法评估方法。
- Extension Interfaces:扩展接口。
接下来,我们就尝试对 4 部分接口进行了解,并学习其使用方法。
分类算法
分类是机器学习面对最多的一类问题,而大多是机器学习算法也着重于解决分类问题。scikit-learn 中能用于分类的算法很多,包括:感知机、人工神经网络、支持向量机、决策树等。详细可以阅读 scikit-learn 文档关于 Supervised learning 中分类算法章节。
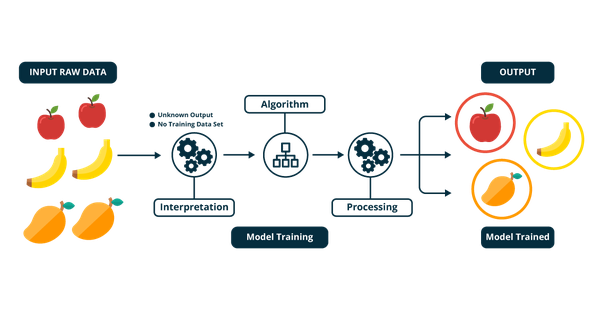
分类问题可以简单概括为:已有了一些数据样本及明确的样本分类。现在从这些样本的特征中总结规律,再用于判断新输入样本到底属于哪一类别。例如下图展示了一个分类过程,使用监督学习算法对水果进行类别区分。
auto-sklearn 中分类算法 API 只有一个,那就是 AutoSklearnClassifier,其包含的参数非常多:
autosklearn.classification.AutoSklearnClassifier(time_left_for_this_task=3600, per_run_time_limit=360, initial_configurations_via_metalearning=25, ensemble_size:int=50, ensemble_nbest=50, ensemble_memory_limit=1024, seed=1, ml_memory_limit=3072, include_estimators=None, exclude_estimators=None, include_preprocessors=None, exclude_preprocessors=None, resampling_strategy='holdout', resampling_strategy_arguments=None, tmp_folder=None, output_folder=None, delete_tmp_folder_after_terminate=True, delete_output_folder_after_terminate=True, shared_mode=False, n_jobs: Optional[int] = None, disable_evaluator_output=False, get_smac_object_callback=None, smac_scenario_args=None, logging_config=None, metadata_directory=None)
下面,详细介绍其中的重要参数:
time_left_for_this_task:模型搜索时间限制(秒)。通过增加此值,auto-sklearn 有更高的机会找到更好的模型,但耗时更久。per_run_time_limit:单次调用模型的时间限制。如果机器学习算法超过该时间限制,则将终止模型拟合。initial_configurations_via_metalearning:超参数优化算法从头开始,还是使用元学习方法。ensemble_size:从算法库中选择构建集成模型的数量。ensemble_memory_limit:整体构建过程的内存限制(MB)。ml_memory_limit:单个机器学习算法的内存限制(MB)。include_estimators:可手动指定一系列备选算法模型,不设置则使用全部可用算法。include_preprocessors:可手动指定一系列备选预处理方法,不设置则使用全部可用预处理方法。resampling_strategy:过拟合处理策略,可选交叉验证,或者 holdout,即按照 67:33 比例对训练测试集进行划分。tmp_folder:配置和日志文件输出目录。output_folder:测试数据预测结果输出目录。
下面,我们尝试使用 auto-sklearn 来完成一个分类建模的例子。这里我们选择 scikit-learn 自带的 DIGITS 手写字符示例数据集。首先,我们导入这个数据集:
import numpy as np
from sklearn.datasets import load_digits
digits = load_digits() # 加载数据集
digits.data.shape, np.unique(digits.target)
可以看到数据集一共 1797 条,包含 64 个特征,而目标值中则有 10 个类别,分别是数字 0 至 9。
如果我们按照标准的 scikit-learn 建模流程。首先,我们尝试将数据切分为划分为 70% 训练集和 30% 测试集。机器学习中,我们习惯采用这样的比例来划分训练集和测试集。
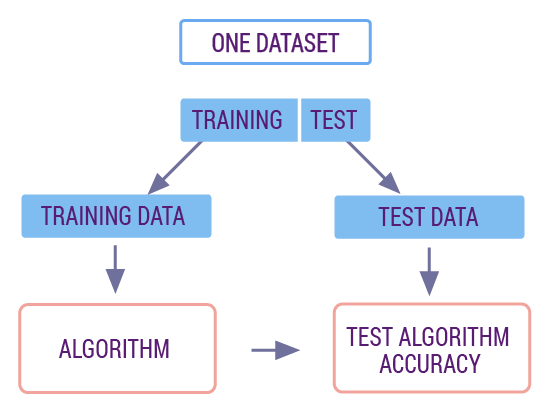
其中训练集用来训练模型,而测试集则用来评估模型的质量。测试集的数据不会出现在训练数据中,这也就类似我们使用了新的数据对训练好的模型进行预测和评估,以保证模型质量真实可靠。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
digits.data, digits.target, test_size=0.3, random_state=42) # 切分数据集
X_train.shape, X_test.shape, y_train.shape, y_test.shape
划分完训练集和测试集之后,我们就可以开始预测了。使用 scikit-learn 去解决一个机器学习相关的问题时,我们的代码都大同小异,主要是由几个部分组成:
- 调用一个机器学习方法构建相应的模型
model,并设置模型参数。 - 使用该机器学习模型提供的
model.fit()方法训练模型。 - 使用该机器学习模型提供的
model.predict()方法用于预测。
下面,首先是从 scikit-learn 中导入决策树分类器。然后使用 .fit 方法训练模型,并使用 .score 得到模型在测试集上的准确度。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train) # 训练
model.score(X_test, y_test) # 评估
不出意外的话,这里得到的测试集准确率大致为 85% 左右。上面是一个集成的 scikit-learn 机器学习建模过程。
接下来,我们尝试使用 auto-sklearn 来对该数据集进行分类。实际上,auto-sklearn 的使用过程包括 API 的名称都和 scikit-learn 是基本一致的。关于 auto-sklearn 支持的分类算法及简称,可以通过 官方代码仓库 查看。
我们定义模型,为了提高搜索速度,这里限制了本次任务的最大搜索时间。由于 auto-sklearn 训练过程有较多的警告,我们选择忽略掉。
import warnings
from autosklearn.classification import AutoSklearnClassifier
warnings.filterwarnings('ignore') # 忽略代码警告
# 限制算法搜索最大时间,更快得到结果
auto_model = AutoSklearnClassifier(
time_left_for_this_task=120, per_run_time_limit=10)
auto_model
然后,使用 .fit 方法训练模型。
auto_model.fit(X_train, y_train) # 训练 2 分钟
auto_model.score(X_test, y_test) # 评估
正常情况下,这里应该会得到好于上面 scikit-learn 使用决策树建模训练的结果。如果效果不理想,你可以把模型的优化时间进一步提高,以便于搜索更优的模型参数。
如果你有条件在线下练习,可以尝试采用 AutoSklearnClassifier 默认参数进行训练,即在全部算法和全部预处理方法上进行建模。正常情况下,你可以得到在测试集上约为 99% 的准确度结果。当然,这需要耗费很长的时间才能得出结果。
auto-sklearn 定义的模型还有其他一些常用的方法。get_models_with_weights 可以返回 auto-sklearn 搜索到的模型信息:
auto_model.get_models_with_weights()
sprint_statistics 可以返回训练过程的关键统计信息,包括数据集名称,使用评估指标,算法运行次数,评估结果等。
auto_model.sprint_statistics()
回归算法
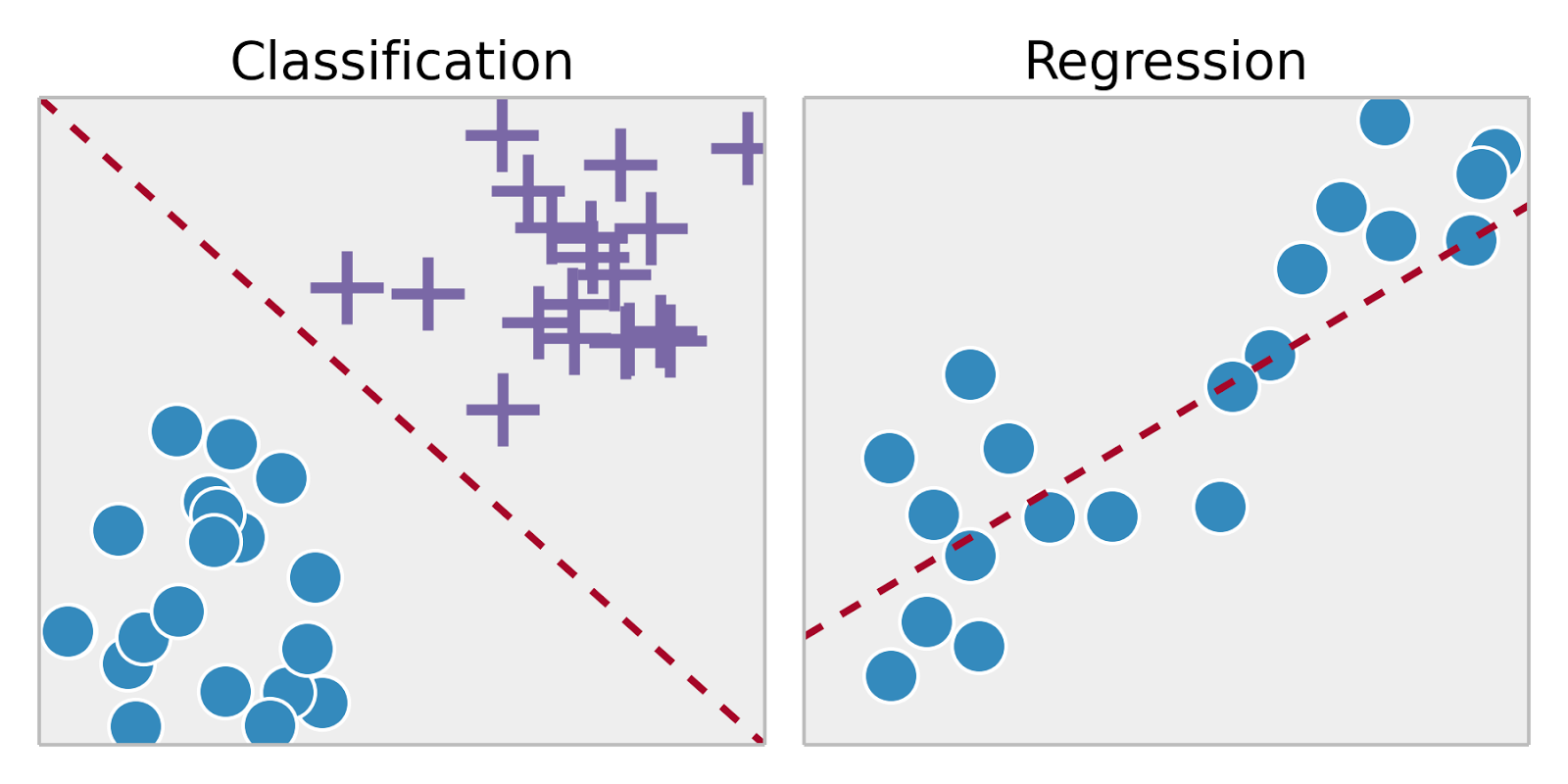
上面,我们学习了 auto-sklearn 解决分类问题的方法。实际上,监督学习(机器学习分支)还包含的另一类方法是回归。回归问题与分类问题的最大区别(特征)在于,输出变量的类型不同。详细说来:
- 分类问题,输出为有限个离散变量,布尔值或者定类变量。例如上面的手写字符识别分类。
- 回归问题,输出为连续变量,一般为实数,也就是一个确切值。例如预测一个人的年龄。
scikit-learn 中包含的线性模型有最小二乘回归、感知机、逻辑回归、岭回归,贝叶斯回归等,由 sklearn.linear_model 模块导入。auto-sklearn 中的回归算法和分类算法相似,其只包含一个核心接口 AutoSklearnRegressor。
autosklearn.regression.AutoSklearnRegressor(time_left_for_this_task=3600, per_run_time_limit=360, initial_configurations_via_metalearning=25, ensemble_size: int = 50, ensemble_nbest=50, ensemble_memory_limit=1024, seed=1, ml_memory_limit=3072, include_estimators=None, exclude_estimators=None, include_preprocessors=None, exclude_preprocessors=None, resampling_strategy='holdout', resampling_strategy_arguments=None, tmp_folder=None, output_folder=None, delete_tmp_folder_after_terminate=True, delete_output_folder_after_terminate=True, shared_mode=False, n_jobs: Optional[int] = None, disable_evaluator_output=False, get_smac_object_callback=None, smac_scenario_args=None, logging_config=None, metadata_directory=None)
仔细观察你就会发现,AutoSklearnRegressor 的参数设置和 AutoSklearnClassifier 几乎完全一致,所以我们就不再对参数的含义进行解释。
机器学习中,一部分分类方法实际上可以用于回归问题的解决。所以,AutoSklearnRegressor 对于回归算法的搜索空间中远不止线性回归、多项式回归这些。其还包括像 K 近邻回归,决策树回归等,详细可以通过 官方代码仓库 查看。
接下来,我们通过运用 scikit-learn 和 auto-sklearn 来解决一个回归问题,这里选择波士顿房价示例数据集。
from sklearn.datasets import load_boston
boston = load_boston() # 加载数据集
boston.data.shape, boston.target.shape
如上所示,数据集包含 13 个特征,目标值为房价实数值。
这里,我们先选择 scikit-learn 中的线性回归方法完成建模。
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(boston.data, boston.target)
model.score(boston.data, boston.target)
这里,.score 返回了回归拟合的 决定系数。决定系数 $R^2$ 在统计学中用于度量应变量的变异中可由自变量解释部分所占的比例,以此来判断统计模型的解释力。简单来讲,决定系数值越接近 1 时,表示相关的方程式参考价值越高。相反,越接近 0 时,表示参考价值越低。
from autosklearn.regression import AutoSklearnRegressor
# 限制算法搜索最大时间,更快得到结果
auto_model = AutoSklearnRegressor(
time_left_for_this_task=120, per_run_time_limit=10)
auto_model.fit(boston.data, boston.target)
auto_model.score(boston.data, boston.target)
正常情况下,这里应该会得到的 $R^2$ 值应高于上面线性回归建模结果。如果效果不理想,你可以把模型的优化时间进一步提高,以便于搜索更优的模型参数。
同样,我们可以返回训练过程的关键统计信息。
auto_model.sprint_statistics()
评估方法
建模预测是机器学习应用的核心,但模型质量的评估必不可少。所以,机器学习中的算法模型都有相对于的评估方法。上面的分类和回归示例中,我们已经认识了两种。分类中,我们常采用预测准确度进行评估,而回归模型的评估不仅有 $R^2$,还有像平均绝对误差,均方误差等。
auto-sklearn 基本上延续了 scikit-learn 中的全部模型评估方法,并放置在 autosklearn.metrics 下方,你也可以到 scikit-learn 官方文档 中去了解这些方法的介绍和使用。
优劣分析
auto-sklearn 使用方法是非常简单的,如果你对 scikit-learn 本身足够熟悉,学习 auto-sklearn 的使用基本没有任何障碍。简单来讲,在 scikit-learn 中建模时,你需要从不同模块下导入不同算法,然后针对算法设置超参数,甚至需要使用网格搜索等高阶调参方法。但是在 auto-sklearn 中,你只需要导入 AutoSklearnClassifier 或者 AutoSklearnRegressor 即可。如果你有足够的时间,对于这两个 API 甚至都不需要设置参数。
但核心的问题也出现了,那就是时间。在前面的示例中,为了更快速地得到结果,实验分别设置了最大时间限制。如果你在本地尝试不设置限制的话,auto-sklearn 执行一次的时间极其漫长。特别地,这还是在 2 个简单的示例数据集上,真实环境中使用的数据往往会复杂很多。
所以,通过 auto-sklearn 的实验,你应该能够进一步感受到自动化机器学习带来的优势和劣势。优势在于使用简单,甚至完全不需要了解算法原理。由于其集成了超参数自动优化,数据自动处理,甚至使用起来要方便快捷很多。而劣势在于,需要耗费漫长的搜索时间,几十分钟、几个小时甚至几天。
除此之外,自动化机器学习并不是万能的,它也可能出现花费大量时间后找不到理想模型的情况。而在这种情况下,如果由机器学习专家处理,可能会更快地发现数据或者算法的问题。
小结
这篇文章中,我们学习了 auto-sklearn 自动化机器学习框架的使用。其中,重点介绍了 auto-sklearn 应用于分类和回归问题的方法及步骤,熟悉了 API 参数并进行了示例练习。此外,重点是体会自动化机器学习带来的优势和劣势,我们必须要提前明白这一点,才能理解如果更好地利用机器学习来帮助自己。
相关链接
系列文章
- 综述及示例
- 线性回归实现与应用
- 多项式回归实现与应用
- 岭回归和 LASSO 回归实现
- 回归模型评价与检验
- 逻辑回归实现与应用
- K-近邻算法实现与应用
- 朴素贝叶斯实现及应用
- 分类模型评价方法
- 支持向量机实现与应用
- 决策树实现与应用
- 装袋和提升集成学习方法
- 划分聚类方法实现与应用
- 层次聚类方法实现与应用
- 主成分分析原理及应用
- 密度聚类方法实现与应用
- 谱聚类及其他聚类方法应用
- 自动化机器学习综述
- 自动化机器学习实践应用
- 模型动态增量训练
- 模型推理与部署
关联推荐
如果你觉得这篇文章对你有帮助,欢迎通过 微信赞赏码 或者 Buy Me a Coffee 请我喝杯 ☕️